On-Policy Distillation: A Tutorial
A research tutorial on On-Policy Distillation (OPD) for LLM- and RL-fluent readers new to OPD as a specific area. Emphasis on OPSD (on-policy self-distillation) and the continual-learning angle.
What this is. A tutorial on On-Policy Distillation (OPD), the technique that has quietly become the consensus closing stage of frontier post-training in late 2025 / early 2026. Written for LLM- and RL-fluent readers who haven’t been tracking the OPD wave specifically.
The one-line claim. OPD trains a student model on its own rollouts, with a teacher providing dense token-level supervision over those rollouts. Keeping the on-policy data of RL but receiving every-token guidance instead of a sparse scalar reward buys roughly 10–100× compute efficiency over RL at matched performance. The applied story is no longer speculative — multiple frontier labs (Qwen, GLM, MiMo, Nemotron) now close their post-training with a recognizably similar OPD stage, and the field published its own survey within ~6 months of the first wave.
Why read this now. The field is in an unusual transitional state. Applied recipes are converging fast — a self-distillation variant, where the same model plays teacher and student, was independently discovered by half a dozen labs in a single quarter — and the easy entry points are closing. But theory lags well behind practice: there is no predictive account of when OPD breaks, no published evaluation on the hard-benchmark regime where ground truth doesn’t reveal the trajectory, and only partial framing of whether a model can become a better teacher to itself over OPD training. This tutorial maps both halves so a reader can decide where to spend research time.
What you get. The main body covers the OPD mechanic, the continual-learning thread that motivates self-distillation, the empirical wins (compute and sample efficiency, learning-without-forgetting, multi-teacher consolidation, cross-modal transfer), the diagnosed pathologies and their published fixes, and the strongest theoretical reframings (OPD-as-KL-RL, distillation-as-IRL, variational inference, and the “the value is being on-policy, not the distillation” critique). Appendices hold the deeper mechanic, the divergence menu, the industrial recipes, and a paper-index excerpt.
Beyond survey content. §9 is open OPD-specific discussion — a candidate research direction, a practical empirical extension, and sharpened versions of the genuinely open problems. §10 zooms out to the broader research vision: OPD as one instance of a multi-year thesis on continual learning from experience, where the hard problems are learnable signal substrates, the mechanism spectrum between in-context learning and weight updates, and what it would mean to build agents motivated to learn rather than rewarded into compliance.
Skim path (~30 min): §1 → §4 → §5 → §7a → §8 → §9 → §10. Vision-only: §8 → §10.
§1 — Hook
Compute. On-policy distillation (OPD) reaches RL-equivalent reasoning performance at 10–100× lower compute. The Qwen3 technical report (Yang et al., 2025) closes its post-training pipeline with a reverse-KL OPD pass that matches the AIME accuracy of its own RL stage at roughly 10× lower cost; Lu (2025, Thinking Machines blog) reports 50–100× savings in the practitioner Tinker setting and frames the gap information-theoretically — O(N) bits per episode for OPD against O(1) for outcome-reward RL.
Frontier-lab consensus. By late-2025 / early-2026, OPD is the closing post-training stage at four frontier labs: Qwen3, GLM-5 (Zhipu AI, 2026), MiMo-V2 (Xiaomi LLM-Core, 2026), and Nemotron-Cascade 2 (NVIDIA, 2026). All four ship OPD as the final stage of the recipe — typically multi-teacher OPSD consolidating per-domain experts — and three of them (GLM-5, MiMo-V2, Nemotron-C2) drop the closing joint-RL pass entirely.
Paper wave. Roughly 25 OPD-family papers landed in 2026 Q1 (Jan–Mar), with another ~20 in 2026 Q2 through mid-May; the field already has its own published OPD Survey (2026) — a sub-field indexes itself only once the literature is too large to track informally.
OPD has gone from niche post-training trick to consensus closing stage of frontier model recipes within ~6 months. This brief covers what it is (§§2–3), why it works (§4), where it fails (§5–6), and where the open research directions are (§7–8).
§2 — The mechanic
On-policy distillation (OPD) trains a student on its own rollouts, with a teacher providing a dense per-token target distribution over each rollout. Two properties together define it. First, the data is on-policy: the student is supervised on sequences it generated under \(p_S(\cdot \mid x)\), not on a fixed teacher corpus, which eliminates the train-inference distribution mismatch that plagues sequence-level KD. Second, the supervision is dense: every position carries a gradient through a per-token divergence \(D(p_S \,\|\, p_T)\), in contrast to RL’s single end-of-trajectory reward. Among the three closest neighbours in post-training, this lands OPD at on-policy + dense — sequence-KD (GKD (Agarwal et al., 2024); MiniLLM (Gu et al., 2024)) sits at off-policy + dense, and verifiable-reward RL (GRPO and friends) at on-policy + sparse.
Information-rate framing
The elevator pitch for an RL-fluent reader is a counting argument. A length-\(N\) rollout under verifiable-reward RL produces a single scalar at the end — \(\mathcal{O}(1)\) bits of supervision per episode. The same rollout under OPD produces a full next-token distribution at every position, i.e. \(\mathcal{O}(N)\) bits per episode, modulo divergence choice and truncation. This is the framing the Tinker blog (Lu, 2025, Thinking Machines blog) uses to motivate the empirical 10–100× compute savings observed when OPD replaces RL as the closing post-training stage (Tinker; Qwen3 (Yang et al., 2025)). OPD inherits the distributional grounding of RL — no exposure bias, since the student is supervised exactly on the support it visits at inference — and the supervision density of KD, without the off-policy mismatch of seq-KD or the sparse-reward degeneracy of RL. The latter matters operationally: under GRPO, all-zero or all-one groups collapse advantages and the gradient vanishes; OPD always has a meaningful gradient whenever \(p_T \neq p_S\).
Objective and pseudocode
The OPD loss is the expected per-token divergence between the student’s and teacher’s next-token distributions, with the expectation taken over rollouts the student itself generates:
\[ \mathcal{L}_{\text{OPD}}(\theta) \;=\; \mathbb{E}_{\,x \sim \mathcal{D},\; \hat{y} \sim p_S(\cdot \mid x;\, \theta)}\!\left[\, \frac{1}{N} \sum_{n=1}^{N} D\!\left( p_S(\cdot \mid x, \hat{y}_{<n};\, \theta) \;\big\|\; p_T(\cdot \mid x, \pi, \hat{y}_{<n}) \right) \,\right] \]
where \(D\) is a divergence (reverse-KL by default — see §2.3), \(\pi\) is any privileged information the teacher conditions on (often empty), and \(\hat{y} = (\hat{y}_1, \ldots, \hat{y}_N)\) is the student’s own rollout under the current \(p_S\). For reverse-KL the per-position term is
\[ D\!\left(p_S \,\|\, p_T\right) \;=\; \sum_{v \in \mathcal{V}} p_S(v) \,\log \frac{p_S(v)}{p_T(v)} \]
summed over the vocabulary \(\mathcal{V}\). The corresponding single training step, modulo bookkeeping:
for x, pi in batch: # pi = privileged info (may be empty)
y_hat = student.sample(x) # student rolls out alone
with torch.no_grad():
p_T = teacher.log_probs(x, pi, y_hat) # ONE forward pass; no teacher sampling
p_S = student.log_probs(x, y_hat)
loss = mean_n( D(p_S[n] || p_T[n]) ) # per-token rev-KL (mode-seeking)
loss.backward(); optimizer.step()Two details are load-bearing. The teacher does not generate — it scores the student’s prefix in one forward pass and emits a next-token distribution over the full vocabulary, conditioned on \(x\), \(\pi\), and \(\hat{y}_{<n}\) (OPSD (Zhao et al., 2026)). And gradients flow only through \(p_S\); the teacher is a fixed target. This makes the teacher cost roughly that of one extra forward pass per student rollout — cheap compared to RL’s group-of-G rollouts plus reward model.
Core loss and the divergence menu
The per-token loss is a divergence \(D(p_S \,\|\, p_T)\) between the student’s distribution and the teacher’s at that position (argument order matches reverse-KL, the industrial default), averaged across positions and summed across the batch. The industrial default is reverse KL, \(\mathrm{KL}(p_S \,\|\, p_T)\) — mode-seeking, so the student concentrates on a peak of the teacher; this is what Tinker and Qwen3 ship. Forward KL, \(\mathrm{KL}(p_T \,\|\, p_S)\), is mass-covering and gives better diversity at the cost of focus — closer to the GKD/MiniLLM lineage.
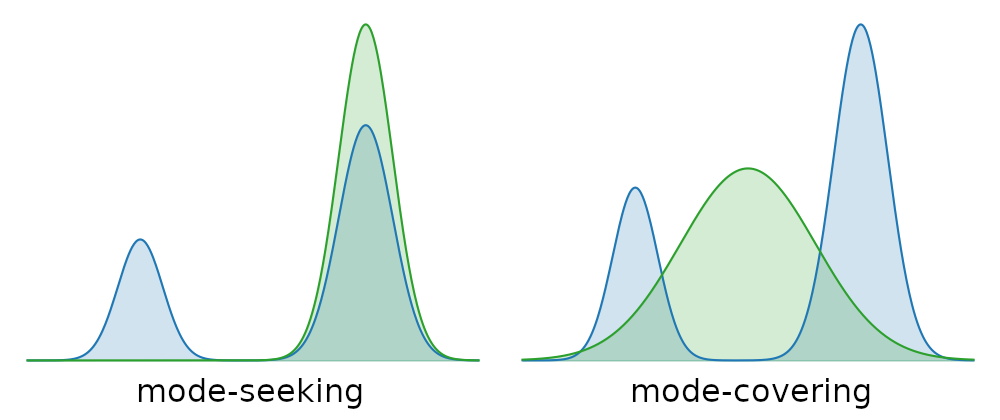
JSD(\(\beta\)) is the symmetric mixture and a pragmatic compromise when rev-KL collapses (OPSD uses \(\beta=0.5\)). Policy-gradient reverse KL (MiniLLM; Tinker) flows gradients through the sampling step and treats per-token KL as advantage, which lets you bolt OPD onto an existing GRPO trainer with minimal infrastructure churn. Full menu, including verbal/discriminator scores and entropy-aware mixes, in App. B.
The teacher–student asymmetry
OPD needs some asymmetry between teacher and student, or the teacher has nothing to teach. The field has converged on three orthogonal axes for manufacturing it, and most concrete methods sit at a specific combination:
| Axis | What’s asymmetric | Canonical instance | Notes |
|---|---|---|---|
| Capability | Teacher is a larger or better-trained model | GKD, MiniLLM, Qwen3 | The classical external-teacher OPD setup; assumes a stronger oracle exists. |
| Privileged information (PI) | Same weights, teacher conditions on something the student does not see at inference (GT, hint, document, …) | OPSD | Removes the “bigger teacher” assumption; the regime where self-improvement is feasible. |
| Time / lag | Teacher is a frozen, EMA, or near-future checkpoint of the student | EMA-self (e.g., OPSD frozen-self variant) | No external model; the asymmetry is purely temporal. |
The axes compose freely — e.g., OPSD uses both a frozen-self teacher and GT-as-PI, so it sits at PI × time-lag while standard external-teacher OPD is pure capability. EMA-self is the time-lag-only corner: no PI, same architecture, only the checkpoint differs.
PI taxonomy pointer
When the asymmetry axis is PI, the choice of which privileged information the teacher conditions on is the dominant design decision. The 2026 literature has catalogued at least twelve distinct PI forms — ground-truth answer, natural-language hint, source document, action trace, peer rollout, text/environment feedback, near-future-self, skill summary, extracted context, concise-prompt instruction, oracle prefix, multi-modal context — each with its own information-density and distributional-proximity profile. Full table with representative papers in App. A.
§3 — OPSD and continual learning
Why this brief weights OPSD over classical OPD
Classical OPD assumes a capability asymmetry — there is a bigger, better teacher waiting in the wings. That assumption is increasingly the binding constraint: at the frontier, a strictly stronger oracle may not exist, and even when it does, paying for its rollouts at every adaptation step is uneconomic. On-policy self-distillation (OPSD) sidesteps the assumption entirely. The teacher and student share weights, and the asymmetry is manufactured at training time via privileged information (ground truth, a hint, a document, a peer rollout, a near-future checkpoint of the model itself — see §2 and App. A). The student is its own teacher, conditioned on something it won’t have at inference. This is the only form of OPD where compounding self-improvement is mechanically feasible without a perpetually-stronger external oracle, which is why the rest of this brief leans on it.
A continual-learning thread runs through the OPSD literature
The strongest single-paper demonstration is SDFT (Shenfeld et al., 2026): training Qwen-2.5-7B sequentially on Tool-Use → Science Q&A → Medical, EMA-OPSD accumulates skills with little oscillation, while SFT shows the classic catastrophic-forgetting sawtooth — performance on earlier tasks collapses as soon as training shifts to the next. SDFT names this the central capability that distinguishes self-distillation from off-policy SFT.
The general claim sits one level above SDFT, and is established by two complementary papers from outside the OPD-proper literature. RL’s Razor (Shenfeld et al., 2025) shows analytically and empirically that on-policy RL is implicitly biased toward KL-minimal solutions among those that solve a new task, whereas SFT can converge arbitrarily far from the base policy. RbD (Chen et al., 2025; Princeton) makes the matched-performance comparison concrete: on Llama-3.1-8B instruction-following, SFT drops non-target capabilities by 27.8 points while RL drops them by only 3.4, at the same target gain. Ablations isolate on-policy data collection — not KL regularization, not advantage estimation — as the operative mechanism. Read together with SDFT, the picture is: on-policy data is the structural property that preserves non-target capabilities, and OPSD inherits this property automatically while adding the dense per-token signal that off-policy KD has and pure-RL lacks.
Industrial pipelines have already operationalized this. The closing post-training stages of MiMo-V2 (Xiaomi, 2026), GLM-5 (Zhipu, 2026), and Nemotron-Cascade 2 (NVIDIA, 2026) all use OPSD-flavored merges to consolidate per-domain RL/SFT experts into a single student without the catastrophic-forgetting tax that a final joint RL pass would impose — a recipe-level convergence on OPSD-for-CL as the way to combine specialists.
Framing
Self-distillation is the only OPD form that doesn’t require a perpetually-stronger external teacher, so it’s the regime where compounding learning over time is feasible. The continual-learning angle is what makes OPSD a candidate unifying mechanism for deploy-learn-deploy LLM development — adapt to a new task, retain the old ones, and the next adaptation starts from a stronger base that is still itself. This framing underwrites §4’s strengths section and motivates the §7 open problems on hard-benchmark and meta-OPD regimes.
§4 — Strengths
OPD is the consensus closing stage of frontier post-training recipes for reasons that are concrete and measurable. The themes below collect the published evidence; the pathologies in §5 then identify where this same form fails.
Compute efficiency. OPD reaches RL-matched reasoning at an order of magnitude less compute. Qwen3 (Yang et al., 2025) closes post-training with reverse-KL OPD and reports ~10× lower cost than its own RL baseline at matched AIME’24 accuracy; Tinker (Lu, 2025, Thinking Machines blog) reports 50–100× savings in practitioner settings using the same recipe over Qwen3 via LoRA. The headline RL-replacement claim is not a single-paper artefact.
Sample efficiency. Independent reformulations show the per-sample signal is dense enough to replace bulk RL. REOPOLD (Ko et al., 2026) recasts OPD as policy-gradient with clipped log-ratio reward and reports 6.7–12× sample efficiency over ProRL on AIME-25 and MathVista; Fast-OPD (Yin et al., 2026) shows 2–47× FLOP reduction via prefix-truncated rollouts while matching full-trajectory OPD accuracy.
Continual learning without catastrophic forgetting. SDFT (Shenfeld et al., 2026) trains sequentially on Tool-Use → Science Q&A → Medical and accumulates skills where matched-budget SFT oscillates catastrophically — the same-model EMA teacher acts as a regularizer toward solutions KL-close to the previous policy. This is the cleanest published demonstration that on-policy self-distillation is not just an efficiency trick but a candidate mechanism for deploy-learn-deploy LLM development; the on-policy-data side of the story is reinforced by RbD and RL’s Razor.
Frontier-lab deployment at scale. By Q1 2026 OPD is the closing post-training stage in multiple frontier recipes — and the evidence is internal-pipeline ablation, not benchmark-cherry-picking. MiMo-V2 (Xiaomi LLM-Core, 2026) uses Multi-Teacher OPD as the final stage of a 309B-MoE / 15B-active student on Olympiad reasoning + agentic; GLM-5 (Zhipu AI, 2026) ends its pipeline with an OPD-merge of expert teachers and replaces a closing joint-RL pass; Nemotron-Cascade 2 (NVIDIA, 2026) takes a 30B MoE (3B active) to ICPC / IMO / IOI gold via Multi-Domain OPSD consolidation of per-domain experts. Three independent labs, three different MoE recipes, OPD in the same structural slot.
OPSD reaches non-trivial domains. Same-model self-distillation, the most demanding OPD variant, holds up on real workloads. OPSD (Zhao et al., 2026) reports 4–8× token efficiency over GRPO on math reasoning; OPSDC (Sang et al., 2026) reduces output tokens by 57–59% with +9–16pp accuracy by conditioning the same-model teacher on a concise-prompt instruction — distributional shaping replaces explicit reward design. The most striking case is essd (Apple, 2026): on coding tasks, self-distilling on a single unfiltered model-generated completion — even a high-temperature one — improves the student. The signal is in the shape of the distribution being matched, not the curated correctness of the data.
Cross-modal transfer. OPD ports reasoning across modalities without modality-matched reasoning data. VOLD (Chen et al., 2025) transfers a text-LLM’s reasoning to a VLM via on-policy KL + GRPO without visual reasoning data; CORD (Hu et al., 2026) and X-OPD (Lin et al., 2026) close acoustic-semantic / speech-text gaps with the same per-token-KL recipe. The mechanism is modality-agnostic — what transfers is the next-token distribution, not the input format.
OPD can surpass the teacher. The “imitation ceiling” intuition is wrong in practice. ExOPD (Liu et al., 2026) reformulates OPD as KL-RL with reward scale λ; setting λ = 1.25 extrapolates beyond the teacher and yields students that beat the teacher on the same evaluation. OPD is not imitation — it is implicit-reward optimization, and the implicit reward can be pushed past the teacher signal it was derived from.
Convergent discovery as a credibility signal. In January–February 2026, seven independent labs converged on the same same-model PI-OPD construction with overlapping setups but no shared codebase: OPSD, SDFT, SDPO (Hübotter et al., 2026), pi-Distill, RL²F + SML (Klissarov et al., 2026), and GATES. Independent rediscovery on this timescale is a strong negative-result-on-fad signal: this is a genuine mechanism, not a recipe-of-the-month.
OPD is not broken. The pathologies catalogued in §5 identify where its current form fails — they bound the applicability, they do not refute the paradigm.
§5 — Pathologies
§4 covered the regimes where OPD demonstrably wins. This section catalogues where its current form breaks, organized by the mechanism producing the failure rather than by paper. Five buckets, roughly in the order they bite: asymmetry-side signal failures, distributional drift between teacher and student, estimator-level pathologies in the gradient itself, behavioural artifacts the student inherits, and a framing-level gap in how teaching quality is currently treated. Length inflation (DemysOPD (Liu et al., 2026)) and the OPSD capacity floor (~4B per OPSD) are the long tail — see App. C for the extended catalogue.
A. Asymmetry / signal pathologies
When the manufactured teacher–student asymmetry collapses, OPD’s gradient goes with it. The clearest case is GRPO stall on cliff prompts: when the base model’s pass-rate is near zero, a group of \(G\) rollouts returns all-zero rewards, group-relative advantages vanish, and no gradient flows. PI is the operative fix because it manufactures asymmetry where capability and time-lag have nothing to offer — SAGE (Liao et al., 2026) injects self-hint PI to reshape the rollout distribution without modifying the reward; HDPO (Ding, NVIDIA, 2026; the paper from which the cliff prompts term originates) routes hard prompts through hint-augmented direct preference optimization; POPE (Qu et al., 2026) feeds correct oracle-prefix trajectories to seed exploration. A fourth attack lives at the teacher-training level rather than the rollout level: Pedagogical RL (preprint, 2026) trains an RL teacher conditioned on question + solution to generate explanations on prompts the student can’t roll out for itself — same asymmetry-restoration goal, different intervention surface (the teacher’s parameters, not the student’s rollout). All four break the all-zero-advantage degeneracy by introducing privileged information; see §6b and the cliff-prompts theme for the full four-family taxonomy of cliff-prompt fixes.
B. Distributional pathologies
Once asymmetry exists, the second-order failure is the teacher’s distribution drifting too far from the student’s. The dominant mechanism is proximity decay: as the student trains, the top-\(k\) token overlap between teacher and student determines whether the per-token signal gets absorbed or wasted. Rethinking-OPD (Li, Zuo, He et al., 2026, Tsinghua) makes this concrete with three tracking metrics (overlap ratio, overlap-token advantage, entropy gap) and two necessary conditions for OPD success — thinking-pattern compatibility and genuinely-new teacher knowledge. CoPD (Gu et al., 2026) supplies independent empirical support — its motivating pilot study reports Pearson \(r = 0.89\) (\(R^2 = 0.79\)) between top-\(k\) overlap and post-distillation gains. pi-Distill (Penaloza et al., 2026) names the same effect qualitatively as the “distributional cliff”. Signal decay at depth is the within-sequence version of the same family: Rethinking-OPD documents teacher top-\(k\) confidence collapsing at later positions, hollowing out the dense-supervision argument exactly where long-CoT reasoning needs it; TAMTRL (Wang et al., 2026) restores signal at depth by computing per-turn probabilistic rewards from a full-document-context teacher. A related distributional failure is narrow-vs-broad mode collapse: Degrade-SD (Kim et al., 2026) shows EMA self-distillation works on narrow scientific reasoning (chemistry) but crashes on broad math by suppressing epistemic verbalization — tokens like “Wait” and “Hmm” that mark exploration get pushed out by the mode-seeking reverse-KL objective. EOPD (Jin et al., 2026) is the canonical fix: a token-level entropy switch (reverse-KL on low-entropy positions, forward-KL on high-entropy ones) raises high-entropy token retention from 6.8% to 18.5%. The mechanism is distributional rather than asymmetry-side: mode-seeking is the wrong divergence at positions where the teacher’s distribution is itself broad, and EOPD selects the divergence per token by local entropy. Within this bucket, two further mechanisms refine the picture. PI miscalibration under reverse-KL: CaOPD (Zhang et al., 2026) proves the teacher’s distribution is miscalibrated when conditioned on ground truth — its fix decouples direction and magnitude of the per-token target — and RLSD (Li et al., 2026) adds a PI-leakage analysis showing how the conditioning signal contaminates downstream rollouts. Together, CaOPD and RLSD establish that rev-KL with strong PI is structurally miscalibrated, not just empirically noisy. The Flawed Prefix Trap: SCOPE (Zheng et al., 2026) shows the teacher gives noisy guidance on unusual student prefixes — recovery rate drops monotonically with the teacher’s perplexity on the student’s own input, and dual-perspective adaptive weighting is the proposed corrective. Pedagogical RL’s R · G_spike reward (preprint, 2026) is also a distributional fix at the teacher-training level: the G_spike term penalizes teacher outputs that diverge sharply from the student’s natural distribution at any token, making the multiplicative reward non-substitutable — correctness and proximity must hold simultaneously. What distinguishes G_spike from standard KL-regularization is that it constrains peak per-token surprise rather than aggregate / averaged divergence — a teacher sequence can have low mean KL against the student and still fail the constraint if a few tokens carry catastrophic spikes. (Roughly: an \(L_\infty\) constraint on token-level divergence, not an \(L_1\).) This is the same proximity issue Rethinking-OPD frames with metrics, CoPD supports empirically, and pi-Distill names qualitatively — addressed here by a training-time spike-penalty rather than a calibration fix or divergence-choice fix. See §6b for Pedagogical RL’s full treatment.
C. Estimator-level pathologies
A third class lives below the divergence-choice level, in the gradient estimator itself. Two are now documented. Revisit-OPD (Fu et al., 2026) identifies sampled-token bias and clip-boundary saturation — distilling only on the sampled token destabilizes long-CoT training; the fix is top-\(k\) local-support matching. Comedy-KL (Shah et al., 2026) shows that the choice of KL gradient estimator matters more than the choice of KL direction: biased estimators cause training instabilities, and unbiased ones improve both in- and out-of-domain performance.
D. Behavioural pathologies
The estimator can be clean and the distributions close, and the student can still inherit pathological behaviour from PI conditioning. SDFT §5 documents this most clearly: when the teacher is conditioned on a demonstration, the student absorbs PI-conditioned surface phrases like “Based on the text…” and reproduces them even at inference, when no PI is present. The pragmatic fix is masking the loss on the first \(K\) tokens; the principled fix — preventing PI from leaking through any prefix position — is open.
E. Framing-level gap — the teaching-quality question
A fifth pathology sits one level above the others: the field has been treating teaching as an emergent side-effect of being a strong model, when it may be a separate skill. Multiple recent papers converge on this. CoPD quantifies proximity decay as a teaching-side property of the teacher, not just a property of the student’s progress. RL²F (Klissarov et al., 2026) and SML (Sun et al., 2026) demonstrate that teaching capability is a learnable, separable skill — a stronger model is not automatically a better teacher. RLT (Cetin et al., 2025) trains teacher quality directly with a student-anchored reward, and Pedagogical RL (Pedagogical RL preprint, 2026 — pre-paper) flips the problem entirely, having the teacher generate solutions rather than score student tokens. The general “teaching-quality gap” framing — that teaching is a separable skill rather than an emergent side-effect of being a strong model — is no longer novel; multiple papers now converge on it. What is still open is which sub-version of it survives, which §7a takes up as the central organizing question.
The five buckets do not partition cleanly — within (B), proximity decay (across training) and signal decay at depth (across positions in a sequence) are two facets of the same teacher-distribution-losing-structure family, and PI miscalibration (B) is what produces the behavioural leakage in (D). But each bucket has a distinct intervention surface, and that is what matters for choosing where to push. None of these pathologies refute OPD as a paradigm; they bound where its current form applies, and §7 picks up the ones that point toward open research directions.
§6 — Reframings and direct critique
The standard OPD frame — on-policy student rollouts scored token-by-token by a fixed teacher under reverse-KL — is one cut at the problem, not the only one. This section surfaces reframings that recast what OPD is doing (§6a) and a direct critique that attacks the central mechanism by flipping the teacher’s role (§6b).
§6a — Reframings (the field is bigger than the standard OPD frame)
1. OPD as policy gradient with a log-ratio reward — and the consequences of that reformulation. Two papers cast OPD as a particular case of policy gradient where the per-token reward is the teacher–student log-ratio, and each pulls a different consequence out of it. ExOPD (Yang et al., 2026) parameterizes the reward by a scalar λ; setting λ > 1 (they report λ = 1.25) extrapolates the teacher reward beyond the imitation fixed point and lets students surpass their teachers on reasoning benchmarks — the implicit “teacher is the ceiling” assumption is an artifact of λ = 1, not of the paradigm. REOPOLD (Ko et al., 2026) is the operational sibling: it recasts OPD as a PPO-style policy gradient with clipped log-ratio reward, which is what makes the recipe stable inside standard RL training infrastructure. REOPOLD reports 6.7–12× sample efficiency over ProRL on AIME-25 and MathVista — a sharp empirical anchor for the reframing. Together: OPD is not a separate paradigm requiring its own training stack; it’s a particular reward parameterization of policy gradient, with λ as a tunable knob (ExOPD) and PPO-style clipping as the stability mechanism (REOPOLD). The Tinker recipe is essentially this construction.
2. OPD as inverse RL, not divergence-matching. X-KD (Cai & Yuan, 2026) applies Bayesian inverse RL (AVRIL) to recover an implicit reward from teacher behavior, then wraps OPD with an experiential regularizer derived from that reward. The argument is structural: the teacher’s distribution is a proxy for an unobserved value function, and treating OPD as IRL — recover-the-reward, then optimize — exposes design knobs (reward shaping, uncertainty regularization) that the divergence-matching view hides.
3. OPD/RL as point estimates of a broader variational objective. VarReason (Zhou et al., 2025) posits a latent reasoning trace and derives an ELBO over reasoning + answer. Standard GRPO drops out as a point estimate that implicitly down-weights difficult prompts (the ELBO surfaces this bias as a term in the gradient). OPD’s per-token KL likewise sits inside a broader variational family. The reframing is consequential because it predicts pathologies (difficulty bias, mode collapse on hard prompts) that the standard OPD objective treats as empirical surprises.
4. The win is on-policy (or near-policy), not distillation per se. RbD (Chen et al., 2025) and RL’s Razor (Shenfeld, Pari, Agrawal, 2025) jointly argue that on-policy data collection itself — not KL regularization, not advantage estimation, not distillation specifically — is the operative mechanism for preserving non-target capabilities. Llama-3.1-8B loses 27.8pp on non-target tasks under SFT vs 3.4pp under RL at matched target gain. RbD’s spectrum sweep (fully off-policy SFT → approximately on-policy Iterative-SFT with dense per-token supervision on filtered model-generated rollouts → dynamically on-policy RL) finds the approximately-on-policy middle ground captures most of the forgetting-resistance at a fraction of RL’s compute cost — “strictly on-policy” is unnecessary; “approximately on-policy” suffices, converging with Pedagogical RL’s explicit lightly off-policy design (§6b).
Three adjacent empirical threads frame the same forgetting-resistance through different mechanism lenses: RL-Subnet (Mukherjee, Yuan, Hakkani-Tür, Peng, 2025) — RL induces sparse-subnetwork updates intrinsically (5–30% of params modified, consistent across 7 RL algorithms × 10 LLMs, without explicit sparsity regularization); RFT-Continual (Lai et al., 2025) — group-normalized advantage acts as data-dependent regularization at the advantage-estimator level; Forget-SFTRL (Yuan et al., 2025) — under parameter-update pruning, RL degrades sharply while SFT is robust, implying RL updates are concentrated and task-critical while SFT updates are diffuse and largely redundant. Notably, RL-Subnet itself attributes its observed sparsity to on-policy data (not KL, not advantage), which suggests these may be downstream effects of on-policyness rather than competing explanations. The convergence question is taken up in §6c.
Reframed against OPD: if being on-policy is the load-bearing axis, the distillation framing carries less weight than its name suggests; the teacher’s per-token signal is one good way to label on-policy data, not a paradigm shift.
5. OPD as a fragile communication protocol over a local menu. A synthesis by Zhuokai Zhao (Meta AI Research) — X thread, 2026 — reframes OPD as a communication protocol between teacher and student: at each position the teacher signals not over the full 150K-token vocabulary but over a small local menu of plausible next-token choices the student might take. Under this lens the four failure modes documented across Rethinking-OPD, DemysOPD, and Revisit-OPD — teacher and student speaking through different-language menus (low top-k overlap), locally-rewarded repetition (the menu collapsing to a self-confirming loop), one-token-as-menu-proxy (the sampled-token estimator standing in for the full menu and inheriting its bias), and per-position gradient cancellation (signal at depth getting averaged into noise) — are not four independent bugs but four facets of the same menu-protocol breaking. The synthesis-level framing is not present in any single source paper; the empirical claims defer to those papers.
6. OPD as distributional-alignment weighting, not on-policy enforcement. DDT (Zhang, Liu, Lin et al., 2026) — Distribution Discriminant Theory — introduces the Centered Log-Likelihood (CLL) statistic \(\varphi_t(x_t) = \log p_t(x_t) + H[p_t]\) that quantifies per-token in-distribution-ness by subtracting the next-token entropy from the log-likelihood (so the statistic normalizes for inherent next-token uncertainty rather than confounding it with distributional misalignment). DDT proves \(\varphi_t\) is a zero-mean martingale under in-distribution data and exhibits negative drift under out-of-distribution data, making it a measurable signal-to-noise indicator of distributional alignment. The reframing: the SFT-vs-RL gap is not fundamentally about on-policy vs off-policy data per se; it is about distributional alignment between data and the model’s current state. DDT’s two applications — In-Distribution Fine-Tuning (per-token loss adaptively modulated by \(\varphi_t\)) and Hinted Decoding — show that off-policy SFT weighted by CLL can match RL accuracy at SFT cost. Read against entry #4 above: where RbD/RL’s Razor identify on-policyness as the operative variable for capability preservation, DDT identifies measurable per-token distributional alignment, of which on-policy rollouts are one (coarse) way to achieve it. The two claims compete on what’s actually doing the work — and DDT’s reframing is the more granular one, since CLL can be computed and weighted on any data, including the off-policy regime where the RbD claim should not apply.
§6b — Direct critique (the antagonist)
The strongest current alternative to mainstream OPSD comes from a coupled pair of papers that attack the teaching-quality gap from a flipped angle: instead of scoring student tokens with a teacher conditioned on privileged information (PI), they train an RL teacher that takes question + solution as input and generates an explanation. The teacher “connects the dots” given the answer; the student then learns from those explanations.
RLT (Cetin, Zhao, Tang; Sakana AI, 2025) introduces the flip with an additive reward r = r_SS − λ · r_KL, where r_SS is the student’s log-probability of the correct solution given the teacher’s explanation, and r_KL measures how interpretable the teacher’s think-tokens are under the student. A 7B RLT teacher beats much larger off-the-shelf teachers as a distillation source — empirical evidence that teaching is a learnable skill distinct from solving.
Pedagogical RL (preprint, 2026) critiques RLT’s additive form directly. Its position: correctness and learnability are not substitutable — an additive reward lets the teacher trade correctness for learnability (or vice versa) at the margin, but real teaching requires both simultaneously. The proposed multiplicative form R · G_spike (correctness reward gated by a learnability spike) makes the two non-substitutable and reports +9pp on MATH over RLT’s additive baseline. Reframed against OPD: standard OPSD treats correctness and learnability as substitutable through the divergence weighting — but they’re not.
A second deliberate departure: Pedagogical RL is lightly off-policy by design. The paper is explicit about this — the teacher-generated explanations (PI-conditioned) become “self-bootstrapped lightly off-policy mid-training trajectories” that the student learns from, not the student’s own rollouts. The authors argue that “purely on-policy learning… is becoming a bottleneck” because cliff-prompt rollouts return zero reward and the student has nothing to learn from. By accepting a small off-policy gap — teacher trajectories are close to but not identical to the student’s distribution, since the teacher shares the same base weights but is conditioned on PI — they get a usable training signal where vanilla OPSD has none. This positions Pedagogical RL on a spectrum: GRPO and OPSD at the strictly-on-policy end (no signal under cliff prompts), direct off-policy SFT from an untrained PI-teacher at the far-off-policy end (signal but teacher trajectories often unreachable from the student), and Pedagogical RL in between (PI-teacher shares the student’s weights, so its trajectories are “legible” to the student while still off-policy enough to carry information about hard problems).
Both papers sidestep the within-update OPSD pathologies catalogued in §5 entirely, because they change what is being trained (the teacher, not just the student), what conditions the teacher (question + solution, not just question), and — for Pedagogical RL — whose rollouts the student actually trains on (the teacher’s lightly-off-policy ones, not the student’s own). The within-update fixes (CaOPD’s direction/magnitude decoupling, EOPD’s entropy switch, Revisit-OPD’s top-k support matching) and the train-the-teacher fixes (RLT, Pedagogical RL, RL²F+SML) are not competitors but parallel attacks on the same gap — and the latter currently has the cleaner empirical story for hard reasoning, in part because it relaxes the on-policy constraint where on-policy itself is the bottleneck.
§6c — Open tension worth pursuing: why does on-policy training preserve capability?
Several of the threads cited in §6a #4 bear on the same question — why does on-policy training preserve non-target capabilities better than off-policy SFT — and propose different answers:
- On-policy data hypothesis (RbD, RL’s Razor). RbD’s spectrum sweep isolates the data distribution as the operative variable; Iterative-SFT (on-policy rollouts + dense per-token supervision) captures most of the forgetting-resistance.
- Sparse-subnetwork updates (RL-Subnet, Mukherjee et al., 2025). RL intrinsically updates only 5–30% of parameters across 7 algorithms × 10 LLMs — but the same paper attributes the sparsity itself to on-policy data, not KL or advantage estimation.
- Data-dependent regularization (RFT-Continual, Lai et al., 2025). GRPO’s group-normalized advantage downweights uncertain rollouts, providing implicit regularization at the advantage-estimator level — a mechanism orthogonal to data-distribution alignment.
- Task-critical concentration (Forget-SFTRL, Yuan et al., 2025). Pruning experiments show RL updates are concentrated on task-critical weights while SFT updates are diffuse and largely redundant — a gradient-geometry lens on the same forgetting-resistance phenomenon.
These need not be competing. One natural reading is nested: on-policy data (upstream) → induces sparse, concentrated, task-critical parameter updates (mechanism) → which preserve prior capabilities by leaving most of the network unchanged (downstream). Mukherjee’s explicit attribution of sparsity to on-policyness directly supports this nesting; the practitioner narrative that treats “sparse updates” as an orthogonal alternative to “on-policy data” does not survive that finding cleanly. Lai’s data-dependent-regularization view sits more orthogonally — it identifies the advantage estimator as a co-contributor, predicting that any advantage-aware method should preserve capability better than plain policy gradient.
What the literature has not yet run — and what would close the question — is a controlled study varying on-policyness and effective update sparsity independently on matched data, with continual-learning evaluation across the resulting cells. No published paper does this directly. The open question is whether on-policy data is the single upstream cause of which sparse subnets, group-advantage regularization, and update concentration are different downstream measurements, or whether these are partially independent mechanisms with separate handles.
The takeaway is not which hypothesis wins. It is that capability preservation under post-training is not yet a settled question, and the OPD literature is one of the more useful settings to probe it — OPSD sits in the middle of multiple relevant axes (data distribution, per-token loss density, effective update magnitude, parameter-coverage sparsity) simultaneously. A candidate research direction to weigh, not a question to resolve in the tutorial itself.
§7a — Open problems
This section catalogues open problems where there is published evidence of a gap. Where papers propose partial solutions, they’re cited; where the problem remains open, it’s noted. “Where it stands” describes published state; it does not endorse any particular research direction. Open-ended research-discussion items that sharpen these problems are in §9 (OPD-specific); the broader research vision they sit inside is in §10.
a1 — Predictive theory of OPD success from pre-training observables. The field has substantial empirical infrastructure for diagnosing teacher–student proximity decay: Rethinking-OPD (Li, Zuo, He et al., 2026, Tsinghua) introduces three tracking metrics — overlap ratio (top-\(k\) token overlap), overlap token advantage (distributional alignment on shared tokens), and entropy gap — and isolates two necessary conditions for OPD success: (a) thinking-pattern compatibility (measured by overlap ratio, which rises from 72% to 91% in successful runs; a weaker but pattern-compatible teacher beats a stronger but mismatched one), and (b) the teacher must offer genuinely new capabilities (same-family larger teachers add nothing — only post-trained teachers with new RL skills help). CoPD (Gu et al., 2026) supplies independent empirical support — Pearson \(r = 0.89\) (\(R^2 = 0.79\)) between top-\(k\) token overlap and post-distillation gains. pi-Distill (Penaloza et al., 2026) names the regime qualitatively as the “distributional cliff.”
What remains genuinely open is the predictive theory that would let a practitioner forecast OPD outcomes before training from pre-training observables (initial overlap ratio, task complexity, PI informativeness, model size). Four specific gaps:
- Sufficient conditions, not just necessary. Meeting Rethinking-OPD’s two conditions is necessary but not demonstrated sufficient — the published thresholds are observational ranges, not derived guarantees.
- Predictive thresholds. No closed-form claim of the form “OPD breaks below overlap \(X\) for task complexity \(Y\).” Numbers like the 72% → 91% trajectory come from one experimental setup, not a derived phase boundary.
- Scaling laws. Nothing connecting model size, task complexity, and PI informativeness to OPD absorption capacity in the Chinchilla-style closed-form way that calibrated post-training compute decisions a generation ago.
- Derivational account. The empirical metrics (top-\(k\) overlap especially) are tracked because they work, not because theory predicts they should be load-bearing. Why top-\(k\) overlap and not log-density correlation, Wasserstein distance, or a Fisher-information functional? Information-theoretic answers haven’t appeared.
Partial → open: substantial empirical infrastructure exists; a predictive theory from pre-training observables does not.
a2 — Within-update PI conversion. The within-update OPSD setup — same-model teacher conditioned on PI, producing per-token signal in the same gradient step — has known pathologies (CaOPD’s miscalibration; the Flawed Prefix Trap coined by SCOPE (Zheng et al., 2026) — when the student commits to a logically broken prefix, the teacher’s continuation degenerates into high-entropy noise). The literature has mostly addressed this by changing the setup rather than by repairing within-update OPSD itself: RLT (Cetin, Zhao, Tang, 2025) and Pedagogical RL (Chakraborty, Ziems, et al., 2026, preprint) flip the problem so the teacher generates explanations conditioned on the answer — and Pedagogical RL additionally accepts a lightly off-policy training regime, arguing that purely-on-policy learning is itself the bottleneck on cliff prompts; RL²F (Klissarov et al., 2026) and its companion SML (Klissarov et al., 2026) train the teacher as a separate skill; CaOPD (2026) decouples direction from magnitude for the calibration axis specifically. The pure within-update version — “given any PI form, derive a non-pathological per-token signal in the same update” — remains partial.
a3 — Hard-benchmark regime. The compact-GT-without-derivation × near-zero-pass-rate combination — ARC-AGI, long-horizon agentic tasks, pure-math final-answer benchmarks, DocVQA few-word — is the regime where OPSD’s value proposition is most strained. The mechanism-level concern: knowing the GT does not reveal the solution path, and the teacher-training fixes in a2 face a weakened information source because the teacher conditioned on question + solution still cannot derive the trajectory from the answer alone. Pedagogical RL (Chakraborty, Ziems, et al., 2026, preprint) acknowledges this — “the privileged context \(c\) gives the model a destination, but it still needs to derive trajectories \(\tau\).” But the families differ in how much they depend on solution-revealing-trajectory: in particular, reflection-on-failure approaches (RESD, ERL, SD-Zero) extract signal from the failed attempt itself — hypothesis-revision over the student’s own trajectory — and do not require knowing the derivation in advance. No published paper currently evaluates OPSD methods on this regime at near-zero pass rate, so all priors about which fix family transfers are mechanism-level only. This is the sharpened central open question for the field, and the load-bearing empirical study is “stress-test the published cliff-prompt fix families (reflection-on-failure first) on this regime.” Open and unaddressed.
a4 — Agentic / multi-turn OPD: what is the right unit? Token-level OPD as implemented in single-turn reasoning does not transfer cleanly to multi-turn agentic settings: Skill-SD (Wang et al., 2026) reports vanilla token-OPD reaching just 22.8% accuracy on AppWorld (and 21.9% on Sokoban) where vanilla GRPO reaches 50.9% and 51.6% respectively, and Rethinking-OPD (Li et al., 2026) documents reward-quality degradation with trajectory depth that propagates instability backward. Candidate units have appeared along the granularity axis: TAMTRL (Wang et al., 2026) computes per-turn rewards from a full-document-context teacher; VLA-OPD (Zhong et al., 2026) keeps the token unit in robotic Vision-Language-Action settings; ROPD (Fang et al., 2026) coarsens further to a rubric-conditioned trajectory unit — a weighted pass rate over teacher-induced semantic criteria, where the supervisory signal is one scalar per rollout rather than one per token. ROPD’s motivation is black-box teacher access (see App. B), but its mechanism is also a concrete instantiation of the “rubric-conditioned span” answer to a4: when surface-form mimicry of token-level KL is the wrong target, evaluating the whole rollout against semantic criteria may be the right one. There is no consensus on whether the correct unit is the token, the turn, the decision-point, or a rubric-conditioned span. Open.
a5 — Selective imitation: when not to distill. Sample-level routing between OPD and RL update modes — and, more broadly, adaptive KL weighting when teacher guidance conflicts with reward — is partially addressed in pieces. RLAD (Zhang et al., 2026) routes between OPD and RL per sample; SRPO (Li et al., 2026) does sample-routed unification of GRPO and SDPO; SCOPE (Zheng et al., 2026) gates teacher guidance by its reliability on the student’s prefix; DDT (Zhang, Liu, Lin et al., 2026) introduces a per-token routing variant via the Centered Log-Likelihood statistic — train only on tokens flagged as in-distribution; RbD (Chen et al., 2025) and RL’s Razor (Shenfeld, Pari, Agrawal, 2025) supply the on-policy-data-as-class argument that motivates routing in the first place. The granularity axis matters: RLAD/SRPO/SCOPE route per-sample, DDT per-token. A general routing theory across the OPD-RL spectrum does not yet exist. Partial.
a6 — Meta-OPD / over-time teaching improvement. A question that is asked less than it should be: does the same-model teacher itself become a better teacher as OPSD progresses, measurable independent of student task performance? Published methods that try to improve the teacher do so via various mechanisms — RL²F + SML train the teacher explicitly, RLT RL-trains it, NPO (Yang et al., 2026) uses near-future-self checkpoints, pi-Distill joint-optimizes teacher and student — but none of them measure teaching quality independently of downstream student task performance. The standard EMA-OPSD line (SDFT, SDPO, OPSD) likewise reports student performance only. Whether teaching quality emerges naturally from standard EMA / frozen-self OPSD, and whether it is measurable independent of student accuracy, is largely unstudied in the published literature. Partial → open.
a7 — Systematic PI selection. PI forms have proliferated — GT, nl-hint, document, action-trace, peer-rollout, text-feedback, reflection, near-future-self, skill-summary, extracted-context, concise-prompt, oracle-prefix, multi-modal — and individual papers establish slices: SAGE (Liao et al., 2026) and NuRL (Pan et al., 2025) on student-derived self-hints; RESD (Zhang et al., 2026, preprint), ERL (Shi et al., 2026), and SD-Zero (2026) on reflection-as-PI; OEL (Ye et al., 2026) on skill summaries for online learning; SDPO (Hübotter et al., 2026) on peer rollouts; Skill-SD on skill-conditioned PI in agentic settings; RL²F+SML (Klissarov et al., 2026) cover an adjacent axis — meta-learning the teacher to convert NL feedback into per-token signal — which is “PI generation” rather than a PI form per se. What is missing is a comparative study across PI forms × tasks × pathologies, with a corresponding account of how cheaply PI can be student-derived rather than externally supplied. Fragmented.
These are descriptions of the field’s open frontier, not research-direction pitches. OPD-specific discussion items that sharpen these problems are in §9; the broader continual-learning-from-experience research vision they sit inside is in §10.
§8 — Strategic landscape
OPD is not a corner of the literature anymore; it is also no longer an open frontier. Both halves of that statement matter when deciding where research effort goes.
Signs of saturation
Paper rate and self-indexing. Roughly 25+ OPD-family papers landed in 2026 Q1 alone, and the field has produced its own survey (OPD Survey (Song & Zheng, 2026)) — a literature indexing its own consolidation. When a sub-field publishes a survey within ~6 months of its first wave, the easy entry points are gone: anyone joining now writes against the survey rather than into open space.
Applied convergence. Industrial post-training pipelines have converged on the same closing stage: reverse-KL + multi-teacher OPSD as the final consolidation step. Qwen3 (Yang et al., Qwen Team, 2025), GLM-5 (Zhipu AI, 2026), MiMo-V2 (Xiaomi LLM-Core Team, 2026), and Nemotron-Cascade 2 (NVIDIA, 2026) all deploy a recognizably similar recipe. The applied template is stable; “we applied OPD to domain X and gained Y%” is no longer a contribution-shaped result on its own.
Scoop velocity. Overlapping ideas are now landing within weeks of each other. A concrete data point: a recent reflection-augmented OPSD scoping (see App. D for the project note) was scooped by RESD (Zhang, Li, Yu et al., 2026, preprint) within ~3 weeks. The lesson generalizes beyond that single case: in the corners where the recipe is established and the next step is “plus a known PI form,” industrial labs publish faster than a graduate timeline allows.
Counter-weights — signs of remaining headroom
Industry commercial bets. Two large-capital bets cut against the saturation read. Thinking Machines (Mira Murati, John Schulman; ~$2B seed) is building the Tinker API explicitly around LoRA + OPD — see Lu (2025, Thinking Machines blog) for their canonical statement of the 50–100× compute claim. Adaption Labs (Sara Hooker, ex-Cohere VP AI Research; company press, 2025) is positioned against the raw-scaling race in favor of efficient adaptation, which lands in the same neighborhood. Two well-capitalized firms staking commercial theses on this paradigm — alongside the saturation rate — is the strongest signal that the paradigm still has runway even where the easy recipes do not.
Theoretical primitivity. Applied recipes are months ahead of theory. The empirical infrastructure for diagnosing proximity decay is substantial — Rethinking-OPD (Li et al., 2026) gives three tracking metrics and two necessary conditions for OPD success; CoPD (Gu et al., 2026) supplies an \(r = 0.89\) empirical correlation; pi-Distill (Penaloza et al., 2026) names the regime qualitatively. What’s missing is the predictive layer: no published scaling law for OPD, no closed-form phase boundary, no sufficient conditions or derivational account of why top-\(k\) overlap is the right measurable (see §7a a1 for the full breakdown). The field has empirical metrics, necessary conditions, mechanism diagnoses, and a survey — but no predictive theory of when OPD breaks from pre-training observables. That gap is the kind that rewards depth over throughput.
Hard-benchmark regime untouched. The compact-GT-without-derivation × near-zero-pass-rate combination — ARC-AGI, long-horizon agentic, pure-math final-answer, DocVQA few-word — is absent from current OPSD evaluations (see §7a a3 for the published-evidence statement of this gap). This is the residual genuinely-novel angle now that the broader teaching-quality framing has converged: a regime where knowing GT does not reveal the trajectory and the teacher-training fixes (RLT (Cetin, Zhao, Tang, 2025), Pedagogical RL preprint) lose their information source.
Meta-OPD largely unmeasured. §7a a6 frames the question — does the same-model teacher itself become a better teacher over OPSD training, measurable independent of student task accuracy? — and notes that every published “learn-to-teach” method requires a separate teacher-training stage, while the standard EMA-OPSD line (SDFT (Shenfeld et al., 2026), SDPO (Hübotter et al., 2026), OPSD (Zhao et al., 2026)) measures only student performance. The over-time teaching-improvement question is partially framed but not solved.
Bottom-line read
The right reading is not “abandon OPD.” It is that the highest-value research now sits in two places: directions with theoretical depth — predictive theory of OPD success from pre-training observables (§7a a1), teaching-time scaling, meta-OPD (§7a a6) — and directions that target the hard-benchmark regime where no paper currently evaluates published OPSD methods (§7a a3). Benchmark-chase and applied-recipe directions — “add PI form X to OPSD on task Y” — sit in the part of the field where industrial labs publish on a 3-week clock and a graduate timeline does not compete on throughput. §9 picks up which OPD-specific directions are worth a 6–12 month bet; §10 positions those directions inside the broader continual-learning-from-experience thesis that survives whichever way OPD-field saturation cuts.
§9 — Discussion
Six themed items in three tiers. A1 is a candidate research direction — a recent, less-crowded corner with a sharp residual concern, framed concretely enough to discuss as a project. A2 is a practical empirical extension — a clear validation-grade question that has a relatively binary answer once the experiment is run, lighter on framing-debate than A3–A6. A3–A6 are open discussion topics, each sharpening an open problem from §7a. Where a partial published answer exists, it’s named; where the gap is genuine, that’s said plainly. The broader research vision these items sit inside — continual learning from experience as the multi-year thesis — is in §10.
A1. Pedagogical RL: where does the learnability-metric framing stop working? (candidate research direction)
Pedagogical RL (Chakraborty, Ziems, Huang, Jiang, Bedi, Khattab; MIT/UMD/UND/UCF, May 2026 blog post with early results) flips the standard on-policy distillation setup in a way worth taking seriously. The standard view: the student samples its own rollouts (on-policy), a PI-conditioned teacher provides per-token signal over them. Pedagogical RL’s view: rollout sampling is itself the bottleneck — when the student can’t stumble on success, RL stalls and OPSD distills over rollouts the student wouldn’t generate anyway. Use PI to actively sample trajectories that are both correct and learnable for the student, and train the teacher (the same model conditioned on \(c\)) to produce such trajectories.
The mechanism is concrete. Given a verifiable correctness reward \(R(x, c, \tau)\) and a spike-aware learnability score \(G_{\text{spike}}(\tau \mid x)\) that penalizes large surprise gaps \(d_t = \log[\pi_\theta(a_t^{\max} \mid x, \tau_{<t}) / \pi_\theta(\tau_t \mid x, \tau_{<t})]\) between the student’s argmax token and the teacher’s emitted token (with a temperature \(\beta\) that interpolates between max-token-surprise and average-surprise), the teacher is RL-trained against the pedagogical reward \(R \cdot G_{\text{spike}}\). Trajectories sampled from the trained teacher are then assimilated into the student via surprisal-gated imitation. The maze illustration in the blog is the cleanest depiction: a cheating teacher uses a hidden door the student can’t see (length 14, but the student assigns \(\approx e^{-8.1}\) probability to a critical token); a pedagogy teacher treats the door as locked and takes the longer route (length 22) that stays inside the student’s support. Early results report up to 40% relative gain over GRPO, OPSD, and off-policy SD on two reasoning tasks.
Why this is worth treating as a candidate direction:
- Recent (~May 2026 blog post, early results only). The corner is much less crowded than the saturated OPD recipes; scoop risk is correspondingly lower at the time of writing.
- Framing flip, not a tweak. “Train the teacher’s rollout-generation for learnability” is a perspective shift on the OPD pathology, not an incremental modification of the existing pipeline. The lightly-off-policy stance is part of the design, not a concession.
- Verifiable training objective. The spike-aware learnability score is measurable from the student’s distribution — no human label, no separate verifier needed beyond the existing task verifier.
- Concrete empirical handles for follow-up work. Generate Pedagogical-RL rollouts, generate alternative-method rollouts, compare student exploration behavior. The experimental loop is short.
The residual concern the learnability metric doesn’t address
The spike-aware metric catches one form of PI-induced distortion: large per-token surprise jumps that signal the teacher took an answer-revealing shortcut the student couldn’t have produced. Penalizing \(G_{\text{spike}}\) rules these out by construction.
But there is another form of PI-induced distortion the metric does not catch: under-exploration. A teacher that knows the answer does not need to explore — it can produce a clean, direct, low-surprise path to the solution. Such a rollout is valid, high-reward, learnable in the spike-aware sense, but systematically less exploratory than what a student facing the same problem without the answer would actually need to generate. The maze example illustrates this without addressing it: the pedagogy teacher takes a single long-but-reachable path; it does not try several routes, hit dead ends, backtrack, and reach the goal — which is what a student without the answer doing genuine search would do. Imitating the clean pedagogy-teacher rollout teaches the destination, and the navigation under known reachability — but not the navigation under uncertainty. The exploration / backtracking competence is exactly the kind of capability CoT-trained models gained at scale.
For low-difficulty tasks where the solution path is straightforward given the answer, this distinction may be small. For genuinely-hard tasks where the student would naturally need to search, it may be large — and Pedagogical RL has only been evaluated on two reasoning tasks in the blog post, so the regime-dependence isn’t characterized.
Other open questions about the method’s limits
- Cliff-regime extreme (zero pass-rate). Pedagogical RL’s premise is that there’s some reachable path the spike-aware reward can find. On true cliff prompts — student pass-rate ≈ 0 — no path may be reachable under the student’s distribution at all. Does the spike-aware reward have anything to optimize against in that regime, or does \(G_{\text{spike}}\) collapse toward penalizing all candidate trajectories equally?
- Inheritance of known OPD pathologies. Does Pedagogical RL inherit confidence collapse, entropy collapse, narrow-vs-broad domain asymmetry (the Degrade-SD axis), or trajectory-depth degradation (the Rethinking-OPD axis) in some form? The clean-rollout imitation could amplify student overconfidence by training it on paths with no expressed uncertainty.
- Broad-domain generalization. Two reasoning tasks in the blog post is a slice. Whether the method’s gains hold on multi-turn agentic, long-horizon, multi-task, or non-verifiable settings is unstudied.
- Verifier dependence. The setup requires a verifiable correctness reward \(R(x, c, y) = \mathbb{I}[y = c]\). Tasks where verification is partial, noisy, or open-ended don’t fit the current formulation; whether the spike-aware idea extends to such settings is open.
- The \(\beta\) temperature. The blog notes that \(\beta \to \infty\) approaches max-surprise penalty and \(\beta \to 0\) approaches average-surprise. Where in this spectrum the method actually wants to live, and whether the right \(\beta\) is task-dependent, is unstudied. Per-token max-surprise might be too punitive on hard problems; average-surprise might miss the cheating jumps the maze example is built around.
Why this is a discussion-worthy candidate direction
Several of these questions have direct experimental handles inside the OPD experimental infrastructure (same benchmarks, same baselines, an additional axis of evaluation focused on exploration behavior). The under-exploration question in particular has a clean measurement target — for a held-out hard task, compare (a) the rollouts a Pedagogical-RL teacher generates, (b) the rollouts a successful student generates without PI, (c) some measure of search/backtracking richness in each. If (a) is systematically narrower than (b), the under-exploration concern is real; if it isn’t, the spike-aware metric is doing more work than the under-exploration framing predicts.
Pointers: §7a a1, a2, a3. §10.2 (mechanism spectrum) treats the broader question of which mechanism-class Pedagogical RL belongs to — flip-the-teacher with learnable rollout-generation. App. D RA-OPD’s reflection-on-failure line is an adjacent but different family.
A2. Does OPSD’s continual-learning claim hold at standard-CL-suite scale? (practical empirical extension)
SDFT (Shenfeld et al., 2026) is the cleanest published demonstration of OPSD-as-continual-learning-mechanism — sequential training on Tool-Use → Science Q&A → Medical accumulates skills where matched-budget SFT oscillates catastrophically. The mechanism story (on-policy data preserves non-target capabilities, RbD, RL’s Razor) is independently coherent. §3’s framing of OPSD as a candidate deploy-learn-deploy mechanism rests on this result.
But 3 tasks is small relative to standard continual-learning benchmarks (50+ task suites are common in the CL literature). Several dynamics that wouldn’t show in a 3-task setup could surface at longer sequences: skill interference accumulating non-linearly, EMA teacher drifting past usefulness, accumulated small drifts the 3-task setup doesn’t have time to expose. Whether the SDFT result reflects a robust CL mechanism or a small-suite artifact is not settled by current evidence.
The empirical footprint is clearer than for A3–A6: extend the OPSD recipe to a published CL benchmark suite, compare to standard CL baselines (replay, EWC, LoRA-merge) at the scale that literature uses. The result is informative either direction. If OPSD’s CL claim holds at scale, §3’s framing strengthens and the broader CL-from-experience thesis (§10) has its strongest published piece of mechanism evidence validated at the right scale. If it doesn’t, the field’s CL-positioning of OPSD needs revising — also a publishable result, and one that bears on which directions in A3–A6 / §10 deserve weight.
Open questions:
- Does the on-policy-data argument (RbD) hold at long task sequences, or does it stop being load-bearing past some task count?
- Does the EMA teacher’s regularization continue to work, or does the teacher drift past usefulness after many tasks?
- Are the standard CL benchmarks well-suited to OPSD’s strengths, or do they presuppose mechanisms (replay buffers, parameter isolation) that OPSD bypasses? If the latter, what would a CL benchmark designed for OPSD-style mechanisms even look like?
Pointers: §3 (OPSD-CL framing), §4 (continual-learning win), §10.1 (the broader CL-from-experience thesis this validates a piece of).
A3. Does being better at a task translate to being better at teaching it?
The OPD setup makes a teacher out of a model by conditioning it on privileged information — a reference solution, a hint, an action trace, an answer. PI clearly helps the teacher’s task performance: with the reference solution in context, the teacher solves more reliably than without. But OPD doesn’t actually want the teacher to solve well; it wants the teacher to produce a per-token distribution over the student’s rollout that is learnable signal for the student (the KL the student is trained against). These are related but they are not the same axis. Being better at solving the task and being better at teaching the task are different competencies, and PI improves the former more obviously than the latter.
Zhuokai Zhao (Meta AI Research)’s X-thread synthesis names the structural version of this gap: the teacher distribution \(\pi_T(\cdot\,|\,x, c)\) is treated as an approximation to \(\pi^*(\cdot\,|\,x)\), but at inference the student does not condition on \(c\); what it needs is \(\pi_S^*(\cdot\,|\,x)\). PI-conditioned teachers produce excellent trajectory quality (they solve the task) and systematically wrong distribution shape (they reference the answer, take shortcuts that only make sense given \(c\), produce sequences at very low probability under \(\pi_S(\cdot\,|\,x)\)). Strong solving, weak teaching, in this view, are different facets of the same conditioning.
The empirical pattern is consistent with the gap. Rethinking-OPD (Li et al., 2026) finds a weaker but pattern-compatible teacher beats a stronger but mismatched one — i.e., the teacher’s solving capability is not what’s load-bearing for the student’s gain. CoPD (Gu et al., 2026) measures the same axis quantitatively: Pearson \(r = 0.89\) between top-\(k\) token overlap (a teaching-side quantity) and post-distillation gains — if task-solving had been the operative variable, this correlation wouldn’t be where the signal sits. SDPO and SDFT document student hallucination patterns consistent with matching a teacher whose conditioning the student lacks at inference; CaOPD (Wang et al., 2026) shows the closely-related miscalibration pathology — teacher overconfidence on confidence tokens, a teaching-side defect orthogonal to whether the teacher itself solves correctly. SCOPE (Zheng et al., 2026) names the limit case as the Flawed Prefix Trap: when the student commits to a logically broken prefix, the teacher’s continuation degenerates into high-entropy noise — the teacher’s task skill might still be intact in that moment; its teaching reliability on the student’s specific prefix is what fails.
The literature has already started training the teacher as a teacher rather than relying on PI-conditioning to make it one. RLT (Cetin, Zhao, Tang, 2025) and Pedagogical RL (Chakraborty, Ziems et al., 2026) RL-train the teacher to generate explanations from answers — i.e., they put training pressure directly on the teaching side. RL²F + SML (Klissarov et al., 2026) meta-learn the teacher to convert NL feedback into per-token signal. NPO (Yang et al., 2026) treats which checkpoint to use as the teacher (near-future-self) as itself a learnable choice. pi-Distill joint-optimizes the teacher and student together. Each of these is an admission, by construction, that “make the teacher solve the task better” is not the same intervention as “make the teacher teach the student better.”
The token-level breakdowns in Pathologies §5 — tokenization-mismatch artifacts, equivalent-but-different reasoning paths flagged as wrong, repetition self-reinforcement — also tip into the unit of supervision sub-question (§7a a4): Skill-SD’s 22.8% vs. 50.9% GRPO failure on AppWorld with vanilla token-OPD suggests the token may itself be the wrong granularity for the teaching signal, motivating ROPD’s rubric-conditioned trajectory unit as the dense-but-non-token alternative.
The questions worth keeping open:
- How are task skill and teaching skill related? They’re clearly not independent — a model that can’t solve at all also can’t produce useful per-token signal — but they’re not identical either, as the papers above suggest. Is the relationship monotone, saturating, or non-monotone (where past some point, better task skill starts to hurt teaching because the teacher takes more shortcuts)?
- Is there a training paradigm where a model would jointly improve at the task and at producing learnable teaching signal — i.e., learn to teach as a byproduct of learning to solve, or via a paired objective that pushes on both axes? RLT / Pedagogical RL / RL²F+SML each train one side or the other; whether a coupled training procedure could do both, and what the right coupling would even look like, is open.
- If task-skill and teaching-skill are genuinely distinct axes, do all the per-token interventions in §5 (CaOPD target replacement, SCOPE prefix gating, ROPD’s rubric unit) sit on the teaching axis specifically? If so, what’s the implied set of teaching-side controls a method has independent of changing how the teacher solves?
Pointers: §7a a1, a2, a4, a6. App. D RA-OPD has the closest internal scoping note on this.
A4. Teaching-time scaling: is there a CoT-for-teaching equivalent?
A useful analogy by way of framing: pre-CoT, we expected models to produce answers in one forward pass; chain-of-thought showed that letting models explore the token space — backtrack, double-check, reason — improved performance and opened a new scaling law. OPSD currently expects the teacher to produce per-token credit-assignment in a single forward pass conditioned on PI. The analogous “let the teacher reason about what learning signal to produce, before producing it” has not been tried at inference time.
Closest existing work along the teacher-improvement axis: RLT RL-trains the teacher (pre-computation, separate stage); Pedagogical RL trains the teacher to explain solutions (pre-computation); pi-Distill joint-optimizes teacher and student (still single-pass at inference); RL²F+SML meta-learn the teacher to convert NL feedback into per-token signal (also pre-computation); NPO advances the teacher selection axis by promoting near-future-self checkpoints, which is a coarse form of temporal teaching-time compute. The within-update intervention axis is also populated: CaOPD decouples direction from magnitude on confidence tokens (a teaching-time edit on the teacher’s emitted signal); SCOPE gates teacher guidance by per-token reliability (a teaching-time veto). None of these put compute on the teaching side at inference time in the analogous sense of CoT — multi-lens passes, deliberative prefill, explicit teacher reasoning about which tokens carry credit.
Suggestive internal signal-measurement data (preliminary, non-rigorous setup) gives a signal ladder: bare prefill \(|\text{KL}| = 0.005\) → static PI (\(0.014\)) → self-generated PI (\(0.042\)) → multi-lens 3 ref-free (\(0.062\), oracle) → multi-lens ref-free + answer-based (\(0.088\), oracle). Multi-lens scoring gave ≈+36% in a non-rigorous setup. Deliberative prefill — letting the teacher generate analysis tokens before emitting per-token logprobs — is untested.
The questions worth keeping open:
- Is there a teaching-side analog of CoT’s inference-time scaling — and would we recognize it if we saw it? The CoT analogy is suggestive but the parameterization that made inference-time compute ablatable for problem-solving (tokens spent thinking before answering) doesn’t translate obviously to the teaching side.
- Is the right axis “compute spent on the teaching forward pass” (multi-pass / deliberative-prefill family) or “compute spent on the teacher’s training” (RLT / Pedagogical RL family), or are these the same axis viewed at different time-scales?
- The signal-ladder numbers above are suggestive of something — but are they teaching-time scaling, PI-quality scaling, or an artifact of the specific signal-measurement setup? It isn’t clear which.
Pointers: §7a a1, a2.
A5. The cliff regime and reflection-on-failure
The compact-GT-without-derivation × near-zero-pass-rate combination — ARC-AGI, long-horizon agentic, pure-math final-answer, DocVQA few-word — is where OPSD’s value proposition is most strained. Knowing the GT does not reveal the trajectory, and the teacher-training fixes that work elsewhere (RLT, Pedagogical RL) face a weakened information source. No published OPSD paper currently evaluates on this regime at near-zero pass rate (§7a a3).
The four cliff-prompt fix families differ in how much they depend on solution-revealing trajectory. Hint injection (family 1): SAGE, NuRL, and HDPO (Wang et al., 2026, the explicit “hint-augmented DPO when GRPO stalls on cliff prompts” paper that named the regime) inject teacher-derived hints to break all-zero-advantage degeneracy. Flip-the-teacher (family 2): RLT and Pedagogical RL train the teacher to derive solutions from answers. Both families require the teacher to know enough about the trajectory to inject useful prefixes or generate explanations from the answer. Reflection-on-failure (family 3): RESD, ERL, and SD-Zero extract signal from the student’s own failed attempt — hypothesis revision over the trajectory — and do not require knowing the derivation in advance. Sample / token routing (family 4): SCOPE, RLAD, and DDT decide when to apply teacher guidance versus when to fall back on outcome reward — a complementary axis to which signal to produce.
Two further papers tie the cliff regime to the broader pathology literature. Degrade-SD (and its EOPD entropy-aware fix) document the narrow-vs-broad task asymmetry with epistemic-token suppression. Rethinking-OPD’s depth-degradation finding (top-\(k\) confidence +0.37 → +0.02 with trajectory depth) suggests long trajectories may be cliff-prone. CoPD’s \(r = 0.89\) overlap-vs-gain correlation provides a candidate diagnostic for which prompts fall into the cliff regime in the first place — but whether top-\(k\) overlap captures the cliff pattern as such, or some other prompt-difficulty axis, is unsettled.
The questions worth keeping open:
- Of the four families, which transfers to the cliff regime — and is the transfer story even single-axis? Mechanism-level reasoning suggests family 3 (reflection-on-failure) depends least on solution-revealing trajectory, but mechanism-level reasoning has been wrong about this kind of thing before. (A1’s under-exploration concern is the family-2-specific version of this question; here it generalizes across families.)
- Do the families interact? E.g., a hint-injection method (family 1) combined with reflection-on-failure (family 3) — does each fix a different failure mode the other leaves untouched, or do they conflict?
- What benchmark would let one see the difference between the families on this regime? ARC-AGI is the obvious target name, but it’s perception-heavy; pure-math final-answer (AIME-like) and DocVQA few-word are cleaner candidates — but which of those actually distinguishes the families is itself unclear.
Pointers: §7a a3. App. D RA-OPD project (scooped within ~3 weeks by RESD) sits adjacent to this. A1 covers the Pedagogical-RL-specific extension question — under-exploration as the residual concern beyond the spike-aware learnability metric.
A6. Learnable vs hand-crafted PI
PI forms have proliferated — GT, nl-hint, document, action-trace, peer-rollout, text-feedback, reflection, near-future-self, skill-summary, extracted-context, concise-prompt, oracle-prefix, multi-modal — with individual papers carving slices (SAGE/NuRL self-hints; RESD/ERL/SD-Zero reflection; OEL skill summaries; SDPO peer rollouts; Skill-SD skill-conditioned). The systematic comparative study — which PI helps where, and how much can PI be student-derived rather than externally supplied? — does not exist (§7a a7).
Several papers already shift weight from the “what PI” axis to the “learn the conversion” axis. RLT RL-trains the teacher (the conversion-from-answer is learned, not designed). Pedagogical RL makes the explanation-generation policy learnable. RL²F + SML treat PI conversion itself as a meta-learned function — natural-language feedback in, per-token signal out. pi-Distill joint-optimizes teacher and student under one objective. CaOPD makes the within-update target replacement learnable (decoupled direction and magnitude on confidence tokens). NPO makes teacher-self selection a learned schedule rather than a fixed EMA.
Two empirical anchors are worth surfacing because they constrain how the discussion can proceed without making the discussion about them:
- Copy contamination. Including verbatim student rollout text in PI causes the teacher’s per-token logprob to collapse onto the verbatim text (~91% of tokens at logprob > -0.01 in internal signal-measurement). Whatever “PI” means, it cannot mean “the teacher reads the student’s own output.”
- Distributional vs content-level bandwidth. pi-Distill’s bandwidth bound constrains the full distribution gap; RLSD handles content-level PI-leakage via verifier-magnitude split. These are different constraints, not the same one viewed differently.
The questions worth keeping open:
- Is hand-crafted PI saturated, or does the apparent saturation reflect how recently the axis was opened? Skill-SD’s skill-summary PI is barely a year old. The bitter-lesson read of “hand-crafted PI is a dead end” might be premature.
- Does the form-vs-conversion distinction (PI form is what you give the teacher; PI conversion is how the teacher turns it into signal) survive under joint optimization? If learnable PI generation and learnable PI conversion are co-optimized, do they remain distinguishable, or do they collapse into one learnable component?
- What counts as PI “being student-derived” — does it require no external input at all (pure self-distillation), or does it allow conditioning on environment / verifier signals the student also has at inference?
Pointers: §7a a7.
How these items relate
The six items open different facets. A1 is the most project-shaped — a candidate research direction extending Pedagogical RL’s recently-published learnability framing, with under-exploration as the residual concern its spike-aware metric doesn’t address. A2 is also relatively concrete — a practical empirical question about whether OPSD’s continual-learning claim survives the standard CL-benchmark scale. A3 asks how task skill and teaching skill relate, and whether a paradigm could improve both jointly. A4 asks whether there is a teaching-side analog of CoT’s inference-time scaling. A5 asks how OPD behaves in the cliff regime no published paper has evaluated. A6 asks whether the next phase is more hand-crafted PI or learnable PI generation.
The items are not independent. A1 sits inside A5 as one specific recent fix family worth extending; A1’s “train the teacher for learnability” sits inside A6’s learnable-conversion axis; A2’s CL scaling validates (or refutes) a piece of evidence §10.1 leans on; A4 is one possible reading of what A3’s “improve teaching directly” angle might look like at inference time. The clustering matters less than the choice of where to put research effort — A1 has the clearest near-term project framing, A2 has a clear empirical footprint, A3–A6 are more open-ended.
The frame these items sit inside — and what the work would still be about if OPD itself stops being the right target — is in §10 — Broader research vision.
§10 — Research vision
§9’s discussion items sit inside OPD’s frame. This section zooms out. The point of including it explicitly: even if OPD is saturating (§8), the underlying research interest is broader than OPD itself. A PhD-scale program needs a thesis that survives the saturation of any one sub-field; this section sketches that thesis, with OPD positioned as one early tool inside it.
Three subsections: the universal-signal framing (§10.1), the mechanism-spectrum framing (§10.2), and the intrinsic-motivation framing (§10.3). These items are vision-level, not project-level — they describe the program the research is positioned for, not the immediate experimental target.
None of them can be settled in one paper. Progress on questions this broad comes from stepping stones — experiments that move toward the vision and let us learn from what does or doesn’t hold up. Each subsection below notes briefly what an early stepping stone might look like; the point of any single experiment is to learn which direction has traction, not to solve the question.
The thesis
For autonomous agents engaged in true continual learning from experience, what’s needed is a mechanism that — given a sequence of past experiences — derives learning signal and applies it to the model’s weights, so the model genuinely improves over time. OPD is one early move in this neighborhood: PI as a signal substrate, distillation as the weight-transfer mechanism. The broader vision asks what other signal substrates and what other transfer mechanisms could occupy the same role, and identifies the structural gaps in the current state of practice.
Two reasons this matters for direction-setting:
- OPD’s saturation is local. §8 documents that applied OPD recipes have converged, scoop velocity is weeks-to-months in the established corners, and industrial labs publish faster than a graduate timeline can compete on throughput. But the saturation is within the PI-conditioning corner specifically. The broader frame — experience to weight-level capability — is mostly untouched outside that corner.
- The frame is durable. Autonomous-agent research is one of the dominant directions in current AI; the question “how does an agent get better from its own experience” is unlikely to lose relevance over a multi-year program even if any specific technique falls in and out of fashion. Framing the research around the broader frame, with OPD as one of several tools, hedges against any one tool’s lifecycle.
§10.1 — OPD as one instance of continual learning from experience
The broader framing: PI is one realization of a more general principle — any signal available in the experience stream can serve as dense per-token supervision when properly converted, and any converted signal can drive weight-level learning rather than external-memory accumulation. The experience stream includes the student’s own rollouts (reflection, self-diagnosis, confidence estimates), environment outputs (verifier signals, execution traces, tool outputs), peer rollouts (group-relative comparisons), accumulated skill summaries (online learning), and near-future-self checkpoints. Each has at least one OPD-family paper attached. The unifying frame doesn’t.
The closest published claim that gestures at this is the RbD / RL’s Razor “the value is being on-policy, not distillation” argument — which reframes OPD’s win as the on-policy data property, agnostic to where the supervision signal originates. If that’s right, OPD’s specific choice of PI-as-signal-source is one path; reflection-as-signal-source (RESD, ERL, SD-Zero), env-feedback-as-signal-source (RL²F + SML), self-summary-as-signal-source (OEL — explicit “skill summaries for online learning” setup), peer-rollout-as-signal-source (SDPO), and near-future-self-as-signal-source (NPO) are alternative paths through the same mechanism. The shared substrate is converting an experience-stream signal into dense per-token learning gradient.
Learnable PI generation
Current OPD recipes hand-craft the PI form: ground truth, hint, reference solution, action trace, peer rollout, skill summary, reflection. Each method picks one PI type, fixes it by design, and varies only content within that form. The framing question: can the per-episode learning signal itself be a learned function — generated by the model rather than chosen by the method designer? And further: different tasks plausibly call for different PI types — a coding task might benefit from action-trace-style PI, a math task from reasoning-style PI, an agentic task from skill-summary-style PI — so a method that learns what to generate would adapt the PI form to the task rather than the other way around.
Pieces of this direction are starting to land:
- RL²F + SML meta-learn the teacher to convert natural-language feedback into per-token signal — a learned conversion from a chosen NL-feedback form into usable PI.
- pi-Distill joint-optimizes teacher and student under one objective, making the teacher’s signal-generation learnable inside a fixed action-trace PI form.
- RLT and Pedagogical RL RL-train the teacher’s generation of explanation/solution-derivation rollouts — learned PI generation inside a fixed flip-the-teacher PI form.
What each of these has in common: the PI generator itself is learned, but the type of PI it produces is still picked up front. What appears open is the more general version: a method that learns what kind of PI to generate, conditional on the task — PI type itself as a learned variable, not just PI content within a chosen type. (The narrower learnable-within-a-fixed-form question is §9 A6.)
Open questions:
- Is “PI form” a meaningful axis of variation under learning, or does it collapse — i.e., does a sufficiently expressive learned signal generator produce essentially the same kind of PI regardless of task, modulated only by surface content?
- If different tasks need different PI types, what’s the right framing of the task→PI-form mapping — explicit conditioning, end-to-end optimization that yields the right PI implicitly, something else?
- How does learnable PI interact with the copy-contamination concern (§9 A6)? When the teacher learns to generate its own PI, it has more freedom to also read the student’s rollout — does the copy-contamination problem get worse, easier, or qualitatively different?
The gating challenge is the optimization itself. The generator emits a PI, the PI enters OPD consolidation, and the student may or may not improve — but the signal quality of any individual PI is hard to read off student outcomes directly, since improvement is delayed and credit-assignment back to the PI-generation step isn’t straightforward. Several candidate routes exist — a proxy metric that approximates “good PI” without waiting for downstream student gain (Pedagogical RL’s spike-aware learnability score is one such proxy in a narrower setting); an outer-loop / inner-loop meta-learning setup that trains the generator against a measurable inner-loop signal; or, in the self-distillation case where teacher and student are the same model, a joint objective that pushes on task performance and PI-generation quality at once — but none of them is settled, and this challenge gates much of the rest.
Stepping stone. A concrete experimental shape: the model — playing teacher in a self-distillation setting — gets (question, student rollout, answer) as input, produces a reasoning trace about what to teach this student here, then emits a PI that is fed into the standard OPD consolidation step. The PI form is whatever falls out of the teacher’s reasoning rather than being chosen ahead of time. This setup connects directly to §9 A4 (teaching-time scaling): the teacher uses inference-time compute to decide what teaching signal to produce before producing it — analogous to how a reasoning model uses inference-time compute to decide what answer to produce before producing it. What we’d learn: whether giving the teacher reasoning capacity over (question, rollout, answer) yields a PI that produces a measurably more learnable signal than a hand-crafted PI of any fixed form. This single experiment probes both the learnable-PI and the teaching-time-scaling hypotheses at once.
Reflection vs introspection
A sharper distinction than the OPD literature currently makes:
- Reflection is per-episode: the agent analyzes its own rollout immediately after the fact, producing signal about this trajectory. Family 3 OPD methods (RESD, ERL, SD-Zero) operate here.
- Introspection is cross-episode and derivational: not just maintaining a growing record of past experiences (a textual lesson collection or skill-summary memory is one ingredient — the base layer), but deliberately extracting connections, rules, and abstractions across many experiences and distilling those into capability alongside the per-task skills. The human analog: building mental models from many past situations, then internalizing them so the next encounter doesn’t require deriving the abstraction from scratch (sleep-consolidation, then next-day reflex). OEL takes the cross-episode internalization loop seriously — accumulative trajectory summarization plus on-policy KD-based consolidation — but its extraction step is summarization, not rule- or abstraction-extraction; the knowledge being internalized is “a running record of what worked,” not “the principle underlying many trials.” NPO’s near-future-self teacher selection operates at the per-episode horizon. The variant where the extraction is itself derivational — building mental models from cross-episode patterns and internalizing them — is not in scope for any current OPD-family method.
Some questions the introspection lens raises:
- What is a signal generation mechanism that mines lessons from many past experiences when the relevant signal is not local to any one episode? It is not obvious that one exists, or that the same machinery as per-episode reflection extends naturally to this horizon.
- What is an internalization mechanism that turns mined lessons into weight updates without re-running per-token rollouts? OPD’s mechanism assumes the rollout exists; introspection-derived lessons would arrive abstracted, not as trajectories.
- Is the reflection / introspection distinction stable on closer inspection, or does it collapse — e.g., does sufficiently-rich per-episode reflection cover the same ground introspection points at?
Stepping stone. A natural first step is finding or constructing the test, not building the introspection mechanism — how to do that isn’t concretely understood yet. The setup: a benchmark where the operative skill is rule-extraction from cross-episode patterns — where solving any single sample doesn’t yield the underlying rule, and even running-summary aggregation across many samples doesn’t, because the rule requires derivation rather than memorization or summarization. On such a benchmark, per-episode methods (vanilla OPSD, reflection-based methods) and summary-style cross-episode methods (OEL-style) would both fail in their characteristic ways; an introspection-based method would have to do something different to succeed. What we’d learn first: whether such a discriminating benchmark already exists in current evaluation suites or needs to be constructed, and whether the predicted failure modes actually manifest. Without a benchmark where rule-extraction is clearly distinguishable from summarization, the introspection distinction stays conceptual; with one, the introspection mechanism — whatever it ends up being — becomes the natural next thing to build.
§10.2 — The mechanism spectrum: PI-conditioning is one way to generate dense learning signal from experience
If §10.1’s framing holds — that any signal in the experience stream can serve as dense per-token supervision — then OPD’s specific contribution is its mechanism for converting that signal into a learning gradient: condition a same-model teacher on PI, take its per-token distribution over the student’s rollout, distill. The question is whether that mechanism is the right one, or whether the option space is much larger than the current literature explores.
The questions in §9 A3–A6 each surface what may be a symptom of having committed to PI-conditioning specifically — the task-skill-vs-teaching-skill gap (A3), the single-forward-pass concern (A4), the cliff-regime concern (A5), the copy-contamination and PI-leakage concerns (A6). §9 A1’s candidate-research-direction framing extends Pedagogical RL within the PI-conditioning corner — a specific in-corner fix worth pursuing, distinct from the spectrum question this section asks. One question that follows from looking at A3–A6 collectively: are there alternative mechanisms for generating dense signal from experience, and would they have different symptom sets — or the same symptoms in mutated form?
Some sketches of the mechanism-space (illustrative, not exhaustive, not endorsements):
- PI-conditioning — the OPD default. Teacher conditioned on external signal; student matches its per-token distribution. The questions in §9 A3–A6 surface what its symptoms might be; §9 A1’s Pedagogical RL extension is one in-corner fix attempt worth tracking.
- Reflection-based signal generation (per-episode) — the student analyzes its own rollout (success or failure) and the analysis itself is converted into per-token gradient (RESD, ERL, SD-Zero). No teacher conditioning on external PI; signal comes from the student’s per-episode self-analysis. Symptom set unknown — reflection quality and calibration are candidate concerns but the literature is too young to know how the pattern shakes out.
- Introspection-based signal generation (cross-episode) — the model mines lessons from many past experiences over a long time horizon, and those mined lessons drive weight updates. OEL addresses a version of this — accumulative trajectory summarization plus on-policy KD-based internalization, evaluated at Sokoban-style scale. What remains open is the derivational version: extracting rules / mental models / abstractions from cross-episode patterns rather than maintaining running summaries, and internalizing those. The published external-memory work (Voyager / Reflexion / MemGPT lineage) stops at textual lesson collection without the weight-internalization step. Continual-learning replay methods come closest on the internalization side but replay raw trajectories, not abstracted lessons. See §10.1 reflection-vs-introspection for the framing.
- Joint generation-and-distillation — teacher and student co-optimized under one objective (pi-Distill). PI is still external but the teacher’s signal-generation is learnable rather than fixed.
- Meta-learned signal converters — the model is trained to convert one form of feedback (NL critique, env signal) into per-token signal (RL²F + SML). PI-conditioning is one input; the conversion itself is learned.
- Far-end of the spectrum: signal generation as architectural property. Nested Learning (NL) (Behrouz, Razaviyayn, Zhong, Mirrokni; Google Research; NeurIPS 2025) represents a model together with its training procedure as a set of nested, multi-level optimization problems, each with its own context flow and its own update frequency. Popular gradient-based optimizers (Adam, SGD-with-momentum) are re-interpreted as associative memories that compress gradients; architectures themselves are reframed as systems of nested optimization. A central contribution is a self-modifying learning module — a sequence model that learns to update its own learning algorithm — and a continuum memory system with multi-frequency update rules (fast neurons for short-term patterns, slow neurons for long-term consolidation, by analogy to multi-timescale brain oscillations and sleep consolidation). Continual learning is the explicit motivation: the paper frames current LLMs as suffering a kind of anterograde amnesia — frozen after pre-training, unable to consolidate new memories beyond the in-context window — and proposes the nested-optimization view as the structural fix. Relevance to this spectrum: NL is the most architectural-level answer to “where does learning signal come from” — the learning dynamics themselves are trained components rather than designed conditioning steps, and multi-frequency consolidation is a natural fit for the cross-episode lesson-aggregation horizon §10.1 raises. The mapping to OPD-style framings is loose and would need its own development; NL is listed here as a spectrum endpoint to indicate how wide the option space is.
The point of listing the spectrum isn’t to pick a winner. It’s to keep the option-space visible while the field is still in its early-mechanism phase. OPSD’s saturation (§8) sits inside the PI-conditioning corner specifically; the larger mechanism spectrum is mostly untouched.
Some questions the mechanism-spectrum view raises:
- Are these genuinely different mechanisms, or do they collapse into one under sufficiently general framing? Reflection-based and PI-conditioning both fundamentally ask the model to produce a per-token target conditional on something the student doesn’t have at inference; the something differs, but the architectural footprint may not.
- The symptoms enumerated in §9 (A3–A6) were derived from PI-conditioning. Do alternative mechanisms have entirely different symptom sets, or do A3–A6-like symptoms recur in mutated form? If the latter, the mechanism choice may matter less than the genre-level commitment to dense signal from experience.
- Where would one even start exploring the spectrum? Is the right move “stay close to OPD’s experimental infrastructure and swap mechanisms one at a time” or “build new infrastructure first because OPD’s setup biases toward PI-conditioning-shaped results”? Both have arguments; the literature doesn’t decide between them.
§10.3 — Beyond reward-engineering: agents motivated to learn
A different question from §10.1 and §10.2 — same vision-level layer, but a distinct axis. §10.1 is about what signal drives learning (universal-signal substrate); §10.2 is about what mechanism converts signal into weight update (PI-conditioning vs alternatives). §10.3 is about what objective the agent actually optimizes — not the engineering choice of reward function, but the structural question of what it would mean for an agent to want to learn.
Current RL post-training (verifiable RL, RLHF, agentic RL) trains agents against external reward signals. Agents reliably find ways to game those signals — reward-hacking is by now a widely documented phenomenon across the literature. The standard response is patching: better verifiers, harder reward functions, adversarial reward design, more careful environment construction. Each patch tends to be followed by new hacks. The arms-race dynamic doesn’t stabilize.
The vision-level question this points at: could an agent be intrinsically motivated to learn generalizable skills, in a way that makes reward-hacking unattractive on the agent’s own terms? The argument is structural — reward-hacking produces capabilities that don’t transfer outside the training distribution; a hack is not in the agent’s own long-term interest if its interest were “build skills that work elsewhere.” If “wanting to generalize” could enter what drives training — through architecture, training process, agent-environment setup, or learned objective — reward-hacking might self-deselect rather than requiring external patches.
The natural setting for this question isn’t pure LLM next-token training. It’s an agent interacting with an environment — tools, sandbox, file system, real or simulated world — where exploration and skill accumulation are the substrate of “learning” and external reward is one signal among many. The connection to OPD: OPD-style machinery is a candidate mechanism by which lessons-from-experience could enter the weights (§10.1’s thesis); the intrinsic-motivation framing determines what should drive that internalization in the first place.
This framing overlaps with — but is distinct from — existing intrinsic-motivation work in RL (curiosity, empowerment, learning progress, surprise-based intrinsic reward). Those approaches target exploration in sparse-reward MDPs; the framing here targets reward-hacking-as-default in the LLM/agent post-training setting specifically. It also overlaps with the broader alignment thesis (“build agents that pursue what we actually want”) without being identical to it.
Some questions the framing raises:
- Is “wanting to learn / generalize” expressible as a learning objective at all, or does it require architecture / training process / agent-setup-level intervention? The existing intrinsic-motivation literature has explored proxies (curiosity, learning progress) without addressing reward-hacking-as-default in this setting.
- What would evidence look like? An agent that chooses the harder generalizing path in a setting where a shortcut is available? Some measurable behavioral signature of “treating one’s own future capability as a target”?
- Is reward-hacking truly against the agent’s interest, or only against ours? An agent maximizing a known training-distribution reward gets short-run benefit from hacking; the structural argument requires that the agent care about post-training-distribution performance. Where does that caring come from, if not from yet another external reward?
- Is this discoverable in roughly the current paradigm (with new objectives / training procedures / agent setups), or does it require a fundamentally different paradigm? The intuition is that it’s discoverable; the literature is not informative either way.
This is the most ambitious of the §10 items — closer to a research thesis than a near-term project. It’s worth keeping visible as the kind of question the work in OPD (and the signal-substrate and mechanism questions in §10.1–§10.2) could eventually serve, even though no current paper attacks it directly.
Stepping stone. An early experimental probe here is environment design. Construct a sandbox where the agent has tools, accessible datasets to learn from, and meaningful interaction with the environment — and set it free, in the sense that no specific task reward drives its behavior. Then observe whether anything resembling learning-seeking behavior emerges. An evolutionary variant of the same setup: seed many agents in the sandbox and ask which ones get further — in terms of accumulated capability over a fixed budget — without external reward shaping. The exact details of the sandbox, the form of “freedom,” the operationalization of “seeking learning” are intentionally underspecified; designing them is part of what the first experiment would be for. What we’d learn: whether the conditions for intrinsic learning-seeking are even constructible in a current-paradigm agent setup. Even a negative result — agents that do nothing useful when freed from external reward — would be informative; it would say something concrete about what intrinsic motivation requires that the current paradigm lacks.
How §9 and §10 relate
§9 and §10 are two layers of the same research positioning. §9’s items are OPD-specific — A1 and A2 are concrete enough to function as near-term experiments, A3–A6 are open discussion prompts sharpened against the §7a frontier. §10 frames the broader program those experiments could sit inside, with the stepping-stones above sketching what each direction’s first move could look like.
The framing question for the supervisor conversation: given OPD-field saturation (§8), why is OPD-adjacent work still interesting, and what is it interesting in service of? §10 sketches one answer — the underlying interest is continual learning from experience, and OPD is one tool inside that broader frame rather than the topic itself. Each §10 subsection sketches the kind of first experiment that could move toward the vision; the §9 candidate directions (A1, A2) can each be read as a near-term experiment that lays a tile toward those broader directions. Whether that’s the right framing, or whether the right move is to step out of OPD entirely, is a conversation to have rather than a decision to announce — and the first stepping stones are what would actually inform that decision.
Appendices
Appendix A — Mechanic, deep
§2 gave a 3-line view of the OPD step. This appendix expands it: a richer walk-through of one training step, the comparison table that makes “on-policy + dense” precise, the three asymmetry mechanisms that manufacture a teaching gap, the full PI-form taxonomy, and a closing note on why PI-OPD exists as its own family.
A.1 One training step, expanded
Fix a batch of prompts \(\{x_i\}\) and (optionally) per-prompt privileged information \(\{\pi_i\}\). One step is:
- Sample. The student rolls out unaided, conditioned only on \(x\): \(\hat{y} \sim p_S(\cdot \mid x)\). Standard autoregressive sampling, temperature whatever the trainer uses. The student does not see \(\pi\) — that asymmetry is the entire point.
- Score, in one teacher forward pass. Hand the teacher the sequence \((x, \pi, \hat{y})\) as one concatenated context and read off, at every position \(n\) along \(\hat{y}\), the teacher’s full next-token distribution \(p_T(\cdot \mid x, \pi, \hat{y}_{<n})\). Crucially: the teacher does not generate. It conditions on the student’s already-generated prefix and emits a distribution over the vocabulary — that’s it. As the OPSD overview puts it, “the rationalization happens implicitly through one forward pass — the teacher does not generate tokens, it only produces informed next-token distributions over the student’s trajectory.” No teacher rollout, no resampling, no MCMC. One forward pass with
torch.no_grad(). - Per-token divergence. For each position \(n\), compute \(\ell_n = D\!\left(p_T^{(n)} \,\|\, p_S^{(n)}\right)\) where \(D\) is the chosen divergence (reverse-KL by default; see App. B). Average across \(n\), sum across the batch.
- Backprop. Gradients flow only through \(p_S\); \(p_T\) is a fixed target.
The student-side compute is one autoregressive rollout plus one teacher-conditional forward pass at the rollout’s length — roughly the cost of a single inference call per example. Compare with RL, where the same rollout yields one scalar at the end; you’ve spent essentially the same forward-pass budget and harvested \(O(N)\) supervised positions instead of \(O(1)\). This is the structural reason OPD recipes report 10–100× compute savings versus matched-performance RL.
A subtlety often missed: even when \(\pi\) is the ground-truth solution, the teacher is not being asked to produce that solution. It is being asked, “given that you know \(\pi\), and given the student wrote <this prefix>, what should the next token be?” The teacher’s job is rationalization-in-context — fitting its informed distribution to the student’s trajectory. That’s why a same-weight model can be a useful teacher: the conditioning context, not the parameters, carries the asymmetry.
A.2 Why “on-policy + dense” is special
The frame that makes OPD’s value obvious is to plot three families on two axes — whose distribution is the rollout drawn from (on/off policy) and what shape is the supervision (single scalar at end, full sequence, per-token distribution):
| Method | Data distribution | Supervision shape | Bits per episode |
|---|---|---|---|
| Sequence-level KD (e.g., SeqKD) | Teacher-sampled — off-policy | Whole sequence target | \(O(N)\) |
| RL with verifiable reward (GRPO, …) | Student-sampled — on-policy | Single scalar at end | \(O(1)\) |
| OPD | Student-sampled — on-policy | Per-token distribution | \(O(N)\) |
OPD inherits the distributional grounding of RL — the student is supervised exactly on the trajectories it will produce at inference, so no exposure bias — and the density of KD — every token carries a gradient. The two pathologies that motivate the other rows are absent in OPD: no off-policy mismatch (the killer of seq-KD on long-horizon tasks), and no all-zero-advantage collapse when every rollout in a GRPO group fails or all succeed. OPD always has a non-trivial gradient as long as \(p_T \neq p_S\), which is generically true by construction.
A.3 Three-way asymmetry mechanisms
OPD needs some asymmetry between teacher and student, otherwise the teacher has nothing to teach. The literature has converged on three mechanisms for manufacturing one:
- Capability — the teacher is a different, larger / better-trained model. This is classical OPD: the GKD / MiniLLM / Qwen3 setup. Industrially it generalizes to multi-teacher OPD (MOPD), where several per-domain experts are merged into a single student through dense per-token supervision over the student’s own rollouts; this is the closing stage in MiMo-V2, GLM-5, and Nemotron-Cascade 2.
- Privileged Information (PI) — same weights, asymmetric context. The teacher sees something the student doesn’t: ground truth, a hint, a relevant document, a successful peer rollout, environment feedback. This is the construction underneath the 2026 OPSD wave and the focus of §3. PI is what makes self-distillation non-trivial: the teacher’s parameters don’t dominate the student’s, but its conditioning does.
- Time-lag — same parameter family, different snapshots. A frozen earlier checkpoint, an EMA-tracked teacher, or a “near-future-self” further along the same training run all provide a teaching gradient because the teacher reflects a slightly different policy than the current student. Frozen-self appears in OPSD; EMA-self underpins SDFT; near-future-self is the design choice of NPO (Yang et al., 2026).
These compose. OPSD uses both frozen-self + GT-as-PI — the teacher is the student’s own checkpoint and it sees the ground truth, stacking time-lag with PI. SDFT layers PI on top of EMA. The combinations are the design surface of the field.
A.4 Full PI taxonomy
The PI form determines what counts as “asymmetric context” — and so determines what kind of skill the student can absorb. The 13 forms catalogued here:
| PI form | What the teacher sees | Example paper |
|---|---|---|
GT |
The ground-truth answer / solution | OPSD (Zhao et al., 2026) |
nl-hint (typically self-generated) |
An abstract natural-language hint about how to solve — usually produced by the same model conditioned on PI, so the hint is “self-hint” rather than externally supplied | NuRL (Pan et al., 2025); SAGE (Liao et al., 2026); RL²F (Klissarov et al., 2026); SML (Klissarov et al., 2026) |
document |
A relevant source document | GATES (Stein et al., 2026); OPCD (Ye et al., 2026) |
action-trace |
A frontier model’s tool-call / action sequence (no CoT) | pi-Distill (Penaloza et al., 2026); RLAD (Zhang et al., 2026) |
peer-rollout |
A successful rollout from the student (or a peer at similar skill) | SDPO (Hübotter et al., 2026) |
text-feedback / env-feedback |
Verifier commentary, runtime errors, or environment responses | RLTF (Song et al., 2026); ERL (Shi et al., 2026) |
reflection |
Student-generated post-hoc analysis of its own attempt — what went wrong, what to try next — optionally conditioned on binary outcome, error feedback, or revealed GT. Theory grounding: Epi-Verb (Kim, Luo, Kim et al., 2026) frames epistemic verbalization as a load-bearing information channel in reasoning (companion to Degrade-SD) | RESD (Zhang et al., 2026, preprint); ERL (Shi et al., 2026); SD-Zero (Princeton/UToronto/CMU, 2026) |
near-future-self |
A later checkpoint of the same training run | NPO |
skill-summary |
A natural-language abstraction of a relevant skill | Skill-SD (Wang et al., 2026); OEL (Ye et al., 2026) |
extracted-context |
Just the load-bearing slice of a long input | OPSDL (Zhang et al., 2026) |
concise-prompt |
An instruction to be brief — asymmetry in style, not knowledge | OPSDC (Sang et al., 2026) |
oracle-prefix |
A correct prefix of the trajectory itself | POPE (Qu et al., 2026) |
multi-modal |
A modality the student lacks at inference (vision, audio, …) | covered in App. F under cross-modal transfer |
Two distinctions worth pulling out. First, the nl-hint row aggregates papers that all use self-hints — the hint is generated by the same model (often conditioned on PI like the GT or a compressed reference solution), not retrieved or hand-written. This avoids surface-form mismatch between hint and student rollout, since both come from the same distribution. Second, reflection is structurally distinct from text-feedback: feedback is what the environment says about the attempt (runtime error, verifier verdict); reflection is what the student says about its own attempt (diagnostic, analytical). The two compose — ERL uses environment feedback to condition reflection — but the per-token signal they license differs in what they teach. RESD scores solution tokens with reflection in the teacher’s PI; ERL selectively distills a successful retry-after-reflection back into the first-turn policy; SD-Zero turns binary correctness into a dense self-revision signal by having the model rewrite its own failed attempt.
A note on the “on-policy” framing of self-hint methods. Worth questioning: papers like SAGE generate the student’s training rollouts conditioned on a self-hint that is absent at inference. The rollouts share the student’s parameters but not the student’s inference distribution — which is technically the same lightly-off-policy regime Pedagogical RL is explicit about (see §6b). Most self-hint papers describe themselves as “on-policy” without specifying which sense (parameters vs distribution); only Pedagogical RL names the gap. This is a recurring read-the-papers-carefully moment: “on-policy” can mean rollouts drawn from the inference distribution (the strictest sense) or rollouts drawn from the same model (the looser sense), and the two diverge whenever the training context differs from the inference context — which is precisely the situation hint-injection, PI-conditioning, and reflection-as-PI all create. The looser sense is what most OPSD papers actually do.
Reflection-elicitation is structurally a hint subtype. A unification of the nl-hint and reflection rows above: when the training scaffold prompts the student to reflect on its own attempt given some disclosed feedback (binary outcome, GT, error trace), the elicitation prompt + feedback-level is itself a kind of PI hint in the rollout context — a process hint about how to reason about the attempt, rather than a content hint about the answer. The reflection tokens are the student’s response to this meta-hint. Reflection-as-PI methods (RESD, ERL, SD-Zero) can therefore be read as a process-hint specialization of the hint-injection family (SAGE, HDPO, POPE, NuRL): same machinery (augment rollout context with PI the inference student lacks), different hint level (process vs. content). See cliff-prompts for the consequence of this unification — it is the structural reason reflection-on-failure methods may be the most viable approach for the hard-benchmark regime, since process hints (unlike content hints) don’t require GT to reveal the solution trajectory.
A useful mental model: the PI form is a knob on information density vs distributional proximity. GT is maximally dense but pulls the teacher’s distribution far from the student’s — bad on cliff prompts in one direction (gradient is real but unreachable, the pi-Distill “distributional cliff”); nl-hint is sparser but closer. near-future-self and peer-rollout trade information for proximity by construction. Systematic comparison across PI forms × tasks × pathologies is one of the open problems flagged in §7a (a7).
A.5 PI-OPD’s reason for existence
Why does PI-OPD warrant being its own family rather than a footnote on OPD? Cliff prompts. When the student’s unaided pass-rate on a problem is 0, two things break at once:
- Vanilla OPD with a same-model teacher has no teaching gap — teacher and student produce the same distribution because they are the same model — so \(D(p_S \| p_T) \approx 0\) position-by-position and no gradient flows.
- GRPO has no positive rollout in the group, so all group-centered advantages are zero and the policy gradient identically vanishes (the well-documented “GRPO stall”; see SAGE, POPE).
PI breaks the degeneracy on both sides. With \(\pi\) in hand, the same-weight teacher succeeds on the prompt — its informed next-token distribution actually points toward a correct continuation — so \(p_T(\cdot \mid x, \pi, \hat{y}_{<n}) \neq p_S(\cdot \mid x, \hat{y}_{<n})\) even though the parameters are identical. The student learns at every position despite every rollout being wrong. This is the regime where PI-OPD is not a marginal improvement over OPD but the only on-policy method that produces a non-trivial gradient at all, and it’s the structural reason the 2026 OPSD wave centers on PI-form design.
Appendix C — Pathologies, extended
See §5 for the main pathology table organized by mechanism bucket — asymmetry / distributional / estimator / behavioural / framing-gap (A–E). This appendix collects four further pathologies that share an audience-level property: they are real, named, and reproduced, but each is narrow enough (length scaling, parameter scale, EMA configuration, dataset size) that the main body would have over-weighted them relative to the central five. They matter for practitioners deploying OPD; they don’t change the main-body taxonomy.
C.1 Length inflation and truncation collapse
DemysOPD (Liu et al., 2026) isolates a sharp phase transition during reverse-KL OPD training: response length grows monotonically until it hits the context limit, the truncation rate spikes from near-zero to nearly 100%, and validation accuracy collapses — without any change in the reward design or teacher choice. The mechanism is mechanistic, not statistical. The token-level advantage is \(r_{KL}(x_t \mid x_{<t}) = \log p_T(x_t \mid x_{<t}) - \log p_S(x_t \mid x_{<t})\); once the student enters a locally-repetitive prefix (e.g., a repeated digit or symbol), the teacher’s next-token distribution becomes extremely peaked at the continuation of the repetition, while the student’s distribution lags. The log-ratio on the repeated token is therefore large and positive — DemysOPD reports the per-token advantage on repeated tokens running 4–9× the advantage on regular reasoning tokens once the regime sets in. The gradient update reinforces the repetitive token, the next rollout contains more repetition, the advantage compounds, and the rollout grows until truncation. This is a locally-rewarding pathology — the gradient is doing exactly what the loss tells it to do, and the loss is wrong.
The paper’s proposed fix, Stable-OPD, combines two stabilizations: (i) a mixture loss \(\mathcal{L} = \mathcal{L}_{\mathrm{OPD}} + \alpha\,\mathcal{L}_{\mathrm{SFT}}(D_{\mathrm{gold}})\) that mixes student-rollout OPD with SFT on gold demonstrations to anchor the rollout distribution outside the repetitive attractor; and (ii) a KL trust region \(\beta_{\mathrm{KL}}\,\mathrm{KL}(\pi_{\mathrm{ref}} \| \pi_{\mathrm{student}})\) against the initial checkpoint, bounding how far the policy can drift into the degenerate region. Both are conventional moves on their own — the contribution is the diagnosis of why they are necessary. Stable-OPD improves Qwen2.5-1.5B average accuracy from 28.9% to 36.1% and Qwen2.5-7B to 47.6% on MATH500 / AIME24 / Olympiad-Bench, with truncation and repetition rates held near zero throughout. Cross-reference: this is the same locally-rewarding mechanism that the Revisit-OPD (Fu et al., 2026) sampled-token-bias finding (§5.C) operates on at the divergence-estimator level, and that zhuokaiz (2026, X thread) generalizes as the “local-menu communication protocol” breaking. The three views are compatible.
C.2 Capacity floor for OPSD (~4B parameters)
The continual-learning angle in §3 leans on same-model PI, which presumes the model is large enough to extract usable signal from the privileged conditioning. OPSD (Zhao et al., 2026) measures the threshold directly. Across Qwen3-1.7B, Qwen3-4B, and Qwen3-8B at matched training budget on AIME24/25, HMMT25, and AMO-Bench (avg@16):
| Model | SFT | GRPO | OPD | OPSD |
|---|---|---|---|---|
| Qwen3-1.7B | — | (par) | — | (par) |
| Qwen3-4B | 48.3 | 49.6 | 49.6 | 50.6 |
| Qwen3-8B | — | — | — | clear win |
At 8B OPSD wins consistently over both GRPO and SFT; at 4B it matches or slightly exceeds GRPO; at 1.7B the gains are marginal. The paper’s explanation is mechanistic and worth quoting: “conditioning on \(y^*\) must produce a better-informed next-token distribution. When capacity is insufficient, the teacher signal is weak.” The 1.7B model lacks the in-context-learning capability to convert the ground-truth conditioning into a more informative distribution — the manufactured asymmetry is real on paper but vacuous in the logits, because the frozen-self teacher conditioned on the answer doesn’t actually behave differently enough from the student to produce a non-trivial \(\log p_T - \log p_S\) signal. This is a capability floor on the PI mechanism itself, not on OPSD as a recipe. Implication for §3: the continual-learning thread is sensitive to scale. SDFT’s results are on 7B Llama; Nemotron-Cascade 2 and MiMo-V2 are on tens-of-billions MoE. The “deploy small models continually” framing collapses below ~4B unless the PI mechanism is replaced with one that doesn’t depend on in-context rationalization (e.g., a separate trained teacher per RLT / Pedagogical RL; see §6b).
C.3 Self-reinforcement in EMA / peer-as-self teachers
A subtler pathology that lives at the intersection of D (behavioural) and the framing of “what counts as the teacher’s input”. When the privileged information fed to the teacher includes the student’s own rollout — whether through an aggressive EMA that tracks the student too closely, or through a peer-rollout PI scheme that injects the student’s recent attempt into the teacher context — the teacher’s distribution starts conditioning on the student’s quirks rather than on independent solution structure. The teacher absorbs the student’s errors and re-emits them as supervisory signal; the student becomes more confident on its specific token sequences without its underlying capability improving. SDPO (Hübotter et al., 2026) provides the cleanest empirical evidence (Table 6). With the reprompting template \(f = \text{output} + \text{solution}\) (no student attempt in the teacher context), the trained student reaches 48.9% accuracy with average entropy 0.37. With \(f = y + \text{output} + \text{solution}\) (student’s own attempt \(y\) included), accuracy drops to 44.5% and entropy collapses to 0.23 — a 38% drop in entropy on initially-uncertain tokens. The paper’s diagnosis is explicit: “including [the student’s attempt] biases the teacher towards the student’s attempt … this reduces the entropy of the student’s distribution, particularly for initially uncertain tokens, thereby reducing exploration.”
Mechanically, this is the zhuokaiz (2026, X thread) local-menu pathology at the rollout level rather than the token level: when the teacher’s context includes the student’s own output, the menu of plausible continuations the teacher will positively reinforce is the student’s menu, and the OPD loss becomes a self-reinforcing loop with no external information injection. The fix in SDPO is structural — drop \(y\) from the reprompting template by default, letting the teacher condition only on the environment output and a sample solution. The same risk applies, at lower bandwidth, to EMA teachers with high update rate (small effective time-lag asymmetry) and to peer-as-self setups where the “peer” is a near-copy of the student. The general principle: the teacher’s PI must contain information the student doesn’t already have, or the manufactured asymmetry is fictitious. This is the operational form of the calibration argument CaOPD (Zhang et al., 2026) makes formally for GT-conditioned teachers (§5.B).
C.4 Small-data overfitting under dense supervision
OPD’s per-token signal is dense — every position is a training example — which accelerates memorization on small training sets compared to the sparse per-trajectory signal of RL or the per-sequence signal of SFT. The intuition that OPD therefore overfits faster than its sequence-level counterparts on small datasets is consistent with two adjacent published findings, though no current paper has isolated the qualitative difference from SFT’s overfitting behaviour. Comedy-KL (Shah et al., 2026) shows that biased KL gradient estimators cause out-of-domain performance to degrade specifically — a fingerprint of estimator-driven memorization rather than genuine generalization, and the cleanest published evidence that the dense signal can encode estimator bias into the student’s weights. DASD (Wang et al., 2026) — positioned as a sequence-level distillation framework rather than a strict OPD method — proposes a two-stage temperature curriculum (T = 0.6 cold-start, T = 1.0 broadening) explicitly to address what it calls “inadequate distribution representation” on small reasoning datasets, and reports that the curriculum substantially outperforms either temperature alone. The temperature schedule is doing for the teacher’s sampling what mixture loss does for the student’s rollouts in Stable-OPD — broadening the support seen during training to prevent the dense signal from compressing the student onto a narrow manifold. Whether OPD’s small-data overfitting is qualitatively different from SFT’s, or just SFT’s overfitting accelerated by a denser signal, remains an open question — no published paper directly answers it, and the two adjacent findings above only partially constrain the answer.
None of the four pathologies above changes the §5 taxonomy. C.1 sits inside bucket C (estimator-level pathologies, same family as Revisit-OPD’s sampled-token bias). C.2 is a scale-conditioning of the OPSD mechanic itself rather than a divergence-choice or asymmetry failure, and belongs to the “applicability bounds” rather than the “failure mechanisms” sub-axis. C.3 is the rollout-level analogue of bucket D’s PI-leakage with a self-reinforcement twist that warrants its own treatment. C.4 is the dataset-size axis of bucket C. Practitioners hitting any of these should reach for the cited mitigations; researchers should note that C.2 (the capacity floor) is the only one with a clean mechanistic explanation, and C.4 is the only one that remains genuinely open as a research question.
Appendix D — RA-OPD project reference
Background
In early 2026 I scoped a research direction called Reflection-Augmented On-Policy Distillation (RA-OPD) as one attack on what the tutorial calls the teaching-quality gap — the observation that on tasks with compact ground truth (ARC-AGI grids, DocVQA few-word answers, pure-math final numbers), the OPSD teacher knows what the answer is but not how to derive it from the student’s specific failed attempt. The conjecture: insert student-generated reflection on its own attempt as an intermediate content between solve and teacher-scoring, and use that reflection in one of two distinct roles.
Two aims
The project pursued two simultaneous but logically independent aims.
Aim 1 — Enrich the teacher’s PI beyond compact GT. Have the student produce post-hoc analysis of its own attempt (optionally with GT revealed), then place that analysis in the teacher’s scoring context as additional privileged information. The intuition: when GT is just a number or a grid, the teacher cannot bridge GT → trajectory on its own; but the student, given both its own failed trajectory and the revealed GT, can attempt that bridging post-hoc. That student-voice bridge — same vocabulary, same prefix style, same failure-mode awareness — is qualitatively richer signal for the teacher than the compact GT alone, and easier for the teacher to translate into token-level supervision on the student’s own distribution.
Aim 2 — Train the student to reflect well with less information. Treat reflection tokens as a training target, not just as scaffolding for scoring solution tokens. A student that learns to produce GT-informed-quality reflection given only binary feedback at inference has acquired a meta-cognitive skill that transfers — the same hypothesis-revision loop (“I tried X, it failed; let me try Y”) that hard benchmarks like ARC-AGI reward, and the same epistemic-verbalization that Degrade-SD and Epi-Verb (Kim, Luo, Kim et al., 2026) identify as load-bearing for hard reasoning.
The two aims are independent: Aim 1 is a PI-enrichment claim that survives even if reflection tokens are never scored; Aim 2 is a skill-transfer claim that requires scoring reflection tokens.
Design constraint — no separate teacher-training stage
A distinguishing axis vs the “flip the teacher” family (family 2 in the cliff-prompts theme): RA-OPD keeps the teacher as just the same model conditioned on PI. There is no separate RL loop on the teacher, no extra trained model, no second training stage. The PI is constructed at training time from the student itself — the student generates the reflection, the training scaffold supplies the disclosed feedback level (binary outcome / GT / reference solution / peer’s success) — and the “teacher” forward pass is simply the same model conditioned on this enriched context. The teacher’s quality emerges from PI choice and the model’s existing in-context-rationalization capability, not from a separately-trained teacher policy.
Concretely:
- RL²F and SML (Klissarov et al., 2026) train the teacher-role as a separable skill via online GRPO + Q-priming. The teacher requires a meta-learning pass before it can be deployed in the OPSD update.
- RLT (Cetin, Zhao, Tang; Sakana AI, 2025) RL-trains the teacher with a student-anchored reward (
r = r_SS − λ · r_KL). The teacher is a separate model produced by a separate training run. - Pedagogical RL (preprint, 2026) RL-trains the teacher with a multiplicative
R · G_spikereward. Same structural commitment to a separate teacher-training stage. - RA-OPD: no teacher training. The teacher is the student model with
(prompt, student_attempt, reflection, disclosed_feedback)in context. The single training loop covers everything.
This is not strictly better — separate teacher training lets the teacher specialize, and the train-the-teacher family has empirical wins (RLT’s 7B teacher beating much larger off-the-shelf teachers). But it’s a different point in the design space, and the no-separate-training constraint matters for compounding-self-improvement applications where adding a teacher-training loop changes the deployment story: a continual-learning OPSD setup that requires periodic teacher-retraining is a different infrastructure proposition from one where the same model keeps teaching itself with no extra stage.
Why reflection (as the candidate intermediate content)
Two properties of reflection make it promising:
- Reflection is conditioned on the specific failure mode of the rollout. Unlike a solution, which has to reach a correct answer, a reflection just has to analyze the attempt. A student that produced buggy code can often write reasonable reflection about why — even when it cannot write correct code. Reflection is usually easier than solving, so it is a place the student can produce useful content even on cliff prompts.
- The teacher can judge reflection quality without needing to know how to solve. When reflection is produced at two disclosure levels — one with only binary feedback, one with GT revealed — the teacher can compare them as intra-voice analyses of the same attempt, where the GT-revealed one is strictly more informed by construction. The teacher does not need to bridge GT → trajectory itself; it just compares two student-voice analyses, one provably better-informed than the other.
Named variants
The design space is large — three binary axes (does reflection enter the loss? does reflection enter the teacher’s PI for scoring other tokens? is there a retry?) cross with gating, disclosure-level sequences, prompt style, loss weighting, and multi-round structure. Four named variants emerged as points worth testing.
Variant A — Scored-only reflection (minimum viable form, single round). Student solves, sees feedback, reflects once, episode ends. Teacher scores both solution tokens and reflection tokens with standard PI. Reflection is in the loss, not in the teacher’s PI for scoring other tokens. This tests Aim 2 in isolation: does training the reflect-skill add value, independent of any PI-enrichment effect?
Variant B — Progressive-disclosure cascaded reflections (the signature mechanism). Student reflects \(N\) times under increasing disclosure levels \(L_0 < L_1 < \ldots < L_N\) — for example, \(L_0\) = only the student’s own attempt; \(L_1\) = + binary pass/fail; \(L_2\) = + ground-truth answer; \(L_3\) = + reference solution; \(L_4\) = + peer’s successful trajectory. Reflection \(r_N\) at the most-disclosed level is strictly more informed than \(r_0\) by construction, not by capability. The teacher scores \(\text{solution} + r_0 + \ldots + r_{N-1}\) with \(r_N\) in its PI context; \(r_N\) itself is not scored.
The key claim is that the teacher’s signal on \(r_0\) reduces to an intra-voice comparison — “did the binary-fed analysis of this attempt align with what the same student produced once GT was revealed?” — which the teacher can perform without itself knowing how to solve the problem. This directly attacks the compact-GT-without-derivation regime: rather than asking the teacher to bridge GT → trajectory, the student does that bridging post-hoc, and the teacher just compares two pieces of analysis in the same voice. The asymmetry between \(r_i\) and \(r_N\) is information-content, not capability — and the teacher’s distribution on \(r_0\) tokens downweights the binary-only interpretation toward the GT-informed one.
Variant C — PI-only reflection (ablation companion to Variant A). Reflection tokens carry no loss; reflection enters the teacher’s PI when scoring solution tokens. Tests Aim 1 in isolation: does reflection-as-PI improve solution-token supervision, independent of training the reflect-skill? This is the variant that RESD scooped.
Variant D — Teacher-side reflection (boundary ablation, not strictly RA-OPD). Instead of student-reflection-as-PI, run a second teacher forward-pass where the teacher itself produces a reflection conditioned on the student’s attempt + PI, and use that as added PI for the scoring pass. Companion ablation: if D works but C does not, the value is in reflection-as-PI per se; if C works but D does not, the student-voice property of the reflection is doing the work; if both work, mechanism is reflection-as-PI broadly; if neither works, the entire reflection-as-PI hypothesis is wrong.
Status: scooped on Aim 1 / Variant C by RESD; residual on Aim 2 + Variant B
In May 2026, within roughly three weeks of scoping, RESD (Zhang et al., 2026, preprint) — Learning with Rare Success but Rich Feedback via Reflection-Enhanced Self-Distillation — published precisely the Variant C construction: student-generated reflection on a failed rollout enters the SDPO self-teacher’s PI context; reflection tokens themselves are not scored. The “reflection-as-PI without scoring reflection tokens” headline is no longer novel.
The defensible residual is two-fold:
- Aim 2 (
1a = Y, score reflection tokens). RESD treats reflection as ephemeral prompt scaffolding generated by \(\theta\) at training time; the reflect-skill is not a training target. Whether scoring reflection tokens adds inference-time value beyond using reflection as PI-only is empirically open — RESD does not address it. Holding Variant C \(\approx\) RESD fixed and adding1a = Y(Variant A) would isolate this contribution. - Variant B (progressive-disclosure intra-voice asymmetry). RESD has a single reflection round and a single disclosure level. The same-student-different-disclosure-levels mechanism — the one that makes the teacher’s judgment well-posed without needing to solve the problem — has no RESD analog. This is the angle most directly aimed at the hard-benchmark regime (compact-GT-without-derivation × near-zero-pass-rate).
The residual is no longer actively pursued. Given that the closest comparator landed approximately three weeks after scoping, the prior on “scoop velocity in this corner of the field” has updated against committing the time needed to validate Aim 2 + Variant B before the next paper publishes the same construction. The project is included in this tutorial as a concrete data point on field velocity rather than as an active research direction.
Lesson learned
Picking direction in a fast-moving field requires checking the arxiv firehose more often than seems reasonable. The roughly three-week gap between scoping RA-OPD and RESD’s publication of its core variant is a calibration data point on how thin the lead-time can be. The general principle: where the recipe is established and the next step is “plus a known PI form,” industrial labs publish faster than a graduate timeline allows — and known PI form now includes reflection.
Appendix E — Industrial recipes
Frontier model post-training pipelines have converged on OPD — or, more often, multi-teacher OPD/OPSD — as the closing stage, replacing or supplementing the final RL pass. The pattern is striking enough that it deserves a unified note: four independent industrial labs, across four distinct architectures and benchmark mixes, all landed on the same shape of closing recipe within a roughly twelve-month window. Brief notes on each follow.
Qwen3 (Qwen3, Yang et al., Qwen Team, 2025) introduced the recipe at scale: industrial reverse-KL OPD as the closing post-training stage, distilling from larger Qwen3 variants into smaller siblings of the same family. This is the source of the widely-cited “10× cheaper than RL on AIME” headline. The Qwen3 report frames OPD as the cost-efficient way to land the reasoning capability that earlier stages — SFT and a domain-mix RL pass — have begun but not converged.
GLM-5 (GLM-5, Zhipu AI Team, 2026) goes further: the GLM-5 frontier post-training pipeline trains a set of per-domain expert teachers via RL and then closes with an OPD-merge of those experts into a single unified student — no closing joint-RL pass. OPD here is explicitly positioned as the consolidation mechanism, not just a compute-saver.
MiMo-V2 (MiMo-V2, Xiaomi LLM-Core Team, 2026) names its variant Multi-Teacher OPD (MOPD) and uses it as the final post-training stage for a 309B-parameter MoE with 15B active. The teacher ensemble spans Olympiad-level reasoning experts and agentic-task experts; the student inherits both capability surfaces in a single closing stage.
Nemotron-Cascade 2 (Nemotron-Cascade 2, NVIDIA, 2026) — a 30B MoE with 3B active parameters — reaches Olympiad gold across ICPC, IMO, and IOI via Multi-Domain On-Policy Distillation. The Nemotron-C2 report specifically highlights OPSD’s role in stabilizing their Cascade-RL pipeline across domains; per-domain RL would otherwise interfere destructively when interleaved, and OPSD as the closing consolidation step absorbs the per-domain experts without that interference.
All four recipes treat OPD/OPSD as the consolidation mechanism — the way to merge per-domain expert models into one unified student without the catastrophic forgetting that would result from joint training or naïve weight-averaging.
Appendix F — Paper index excerpt
This appendix excerpts the OPD paper landscape for navigability. The full structured landscape — with Type, Teacher, PI form, Divergence, and Benchmark columns — lives at Knowledge/Subjects/on-policy-distillation/landscape/paper-index.md in the source Obsidian vault. For full bibliographic entries on every paper cited in this tutorial, see references.md.
Wave-by-quarter chart
Paper count by period across the broader OPD field (approximate, drawn from the vault index; the subset cited in this tutorial is smaller — see grouped list below):
Foundational (pre-2024) ████ (4)
2024 – mid-2025 ████ (4)
2025 mid-year ████████ (8)
2026 Q1 (Jan–Feb) ████████████████████████ (~20)
2026 Q1 (March) █████████████████ (~14)
2026 Q2 (Apr–May, partial) ████████████████████████ (~20)The two visible inflection points are the Jan–Feb 2026 OPSD wave (canonical mechanic + a convergence of self-distillation methods from independent groups) and the April–May 2026 follow-on (pathology diagnoses, theoretical reframings, agentic and multi-modal extensions). The field’s first survey (OPD Survey, Song & Zheng, 2026) appears in the Q2 cluster, which is itself a saturation signal.
Cited subset, grouped by period
Foundational (pre-2024). DAgger (on-policy imitation as theoretical ancestor); SeqKD (off-policy baseline OPD improves on); LUPI (Vapnik’s privileged-information framework); STaR (foundational self-improvement loop).
2024 – mid-2025. GKD (foundational on-policy KD with flexible divergence menu); MiniLLM (policy-gradient reverse-KL); Qwen3 (industrial reverse-KL recipe; “10× cheaper than RL on AIME”); Tinker (practitioner statement of the 50–100× compute claim).
2025 mid-year. RLT (RL-trained teacher that takes question + solution and generates explanations — precursor to Pedagogical RL); NuRL (self-generated NL hints as PI); VarReason (variational reframing of OPD/RL as point estimates of an ELBO); VOLD (text-to-VLM reasoning transfer); GAD (GAN-discriminator OPD for black-box teachers); RbD and RL’s Razor (on-policy data preserves non-target capabilities far better than SFT under matched performance).
2026 Q1 (Jan–Feb OPSD wave). OPSD (canonical mechanic for same-model PI-OPD); MiMo-V2 (industrial Multi-Teacher OPD); GLM-5 (frontier OPD-merge of expert teachers); SDFT (EMA-OPSD for continual learning); SDPO (peer-rollout PI for RLVR); pi-Distill (action-trace PI; names the “distributional cliff”); RLTF (text-feedback PI); RL²F and SML (meta-learning the teacher as a separable skill); GATES (document-PI with consensus gating); OVD (verbal-score black-box OPD); ExOPD (λ=1.25 reward extrapolation lets students surpass teachers); RLAD (action-trace + per-sample OPD/RL routing); X-KD (Bayesian IRL reframing of OPD); POPE (oracle-prefix PI); CORD (cross-modal speech-to-text reasoning); SAGE (PI hint injection breaks GRPO’s all-zero-advantage degeneracy); ERL (experience-reflection-consolidation loop).
2026 Q1 (March extensions). EOPD (entropy-aware token-level KL/forward-KL switch); Fast-OPD (prefix truncation; 2–47× FLOP reduction); Stable-OPD (variance-reducing gradient reformulation); DASD (temperature curriculum + mixed-policy phase); DDT (Distribution Discriminant Theory; Centered Log-Likelihood statistic for per-token in-distribution-ness; In-Distribution Fine-Tuning matches RL at SFT cost); OPSDC (concise-prompt PI for reasoning compression); REOPOLD (log-ratio reward reformulation; 6.7–12× sample efficiency); OEL (reward-free post-deployment online learning); OPCD (on-policy context distillation); VLA-OPD (port to robotic Vision-Language-Action models); Nemotron-Cascade 2 (30B-MoE Olympiad-gold via Multi-Domain OPSD); TAMTRL (turn-level rewards from full-document-context teacher); Degrade-SD (narrow-vs-broad asymmetry); X-OPD (speech-text reasoning); HDPO (hint-augmented DPO routing for cliff prompts); Revisit-OPD (top-k local-support matching for long-CoT instability).
2026 Q2 (April–May, partial). CaOPD (provable miscalibration under reverse-KL; direction/magnitude decoupling); essd (Apple — shape beats data quality); RLSD (PI-leakage analysis); NPO (near-future-self as teacher); Skill-SD (skill-summary PI for multi-turn agentic settings); OPSDL (long-context OPSD); SCOPE (Flawed Prefix Trap; dual-perspective adaptive weighting); SRPO (GRPO/SDPO sample-routing); DemysOPD (length inflation diagnosis; Stable-OPD mitigation); Rethinking-OPD (teacher confidence decay at depth); Pedagogical RL (multiplicative R·G_spike critique of RLT’s additive form); CoPD (co-evolving experts as mutual teachers; pilot study reports Pearson r=0.89 between top-k overlap and downstream gains); Comedy-KL (unbiased KL gradient estimators); SD-Zero (self-revision distilled back; reflection-as-PI for the binary-reward regime); ROPD (rubric-based black-box OPD; teacher-induced criteria + Verifier scoring); RESD (reflection-as-PI under SDPO; closest published instantiation of RA-OPD’s reflection variant); OPD Survey (the field’s first published survey).
Beyond the cited subset
The full landscape lists ~80+ papers organized by Type (OPD / OPSD / Hybrid / Theory / Survey), Teacher type (external / frozen-self / EMA-self / joint / near-future / black-box / consensus-gated), PI form (13+ forms — see Appendix A), Divergence (7+ variants — see Appendix B), and Benchmarks. Consult Knowledge/Subjects/on-policy-distillation/landscape/paper-index.md in the source vault, or refer to the OPD Survey (2026) for the field’s published comprehensive coverage.
References
CaOPD — Zhang et al. (2026). Calibrated On-Policy Distillation. https://arxiv.org/abs/2604.16830. Proves that the teacher distribution is miscalibrated under reverse-KL when conditioned on ground truth as PI; decouples direction and magnitude of the per-token target as the corrective.
Comedy-KL — Shah et al. (2026). On KL Gradient Estimator Configurations for On-Policy Distillation. https://arxiv.org/abs/2512.21852. Shows that biased KL gradient estimators cause training instabilities; unbiased estimators improve in- and out-of-domain performance.
CoPD — Gu, N., Yang, Si, Qin, Yao, Fu, Z. Lin, W. Wang, Duan, J. Wang (2026). Co-Evolving Policy Distillation. https://arxiv.org/abs/2604.27083. Training method: experts and a student co-evolve during ongoing RLVR training (rather than after complete expert training), with experts serving as mutual teachers. Motivating pilot study reports Pearson \(r = 0.89\) (\(R^2 = 0.79\)) between top-\(k\) token overlap (behavioral proximity) and post-distillation performance gains — the cleanest published empirical signal that proximity is load-bearing for OPD absorption, though the paper does not frame itself as a monitoring-metric paper.
CORD — Hu, Zhu, Luo, Zhang, He (2026). CORD: Bridging the Audio-Text Reasoning Gap via Weighted On-policy Cross-modal Distillation. https://arxiv.org/abs/2601.16547. On-policy KL distillation closes the acoustic-semantic gap between speech encoders and text reasoners; ports text-LLM reasoning into audio models without paired reasoning data.
Degrade-SD — Kim et al. (2026). When Self-Distillation Degrades: Mode-Collapse on Broad Reasoning Tasks. https://arxiv.org/abs/2603.24472. Diagnoses narrow-vs-broad asymmetry: EMA self-distillation works on narrow scientific reasoning (chemistry) but crashes on broad math by suppressing epistemic verbalization tokens (“Wait”, “Hmm”).
DASD — Wang et al. (2026). Distribution-Aligned Sequence Distillation for Reasoning Models. https://arxiv.org/abs/2601.09088. Two-stage temperature curriculum (T = 0.6 → T = 1.0), divergence-aware sentence sampling, and a lightweight mixed-policy phase; sequence-level distillation framework whose temperature curriculum is a candidate mitigation for small-data overfitting.
DDT — Zhang, M., Liu, Lin, X. Yang, Dai, Luo, W. Jiang, Hou (2026). Towards On-Policy SFT: Distribution Discriminant Theory and its Applications in LLM Training. https://arxiv.org/abs/2602.12222. Introduces a Centered Log-Likelihood statistic \(\varphi_t = \log p_t(x_t) + H[p_t]\) that quantifies per-token in-distribution-ness (zero-mean martingale under in-distribution, negative drift under OOD). Two applications: In-Distribution Fine-Tuning (per-token loss modulation by \(\varphi_t\)) and Hinted Decoding. Claims off-policy SFT weighted by CLL matches RL accuracy at SFT cost — reframes the SFT-vs-RL gap as distributional alignment rather than on-policyness.
DemysOPD — Liu et al. (2026). Demystifying OPD: Length Inflation and Stabilization Strategies for Large Language Models. https://arxiv.org/abs/2604.08527. Identifies “Abrupt Repetition Saturation” — repeated tokens systematically receive larger token-level \(r_{KL}\) advantages than constructive ones, producing length inflation and truncation collapse; proposes Stable-OPD (mixture loss with gold demonstrations + KL trust region against the initial checkpoint).
EOPD — Jin et al. (2026). Entropy-Aware On-Policy Distillation. https://arxiv.org/abs/2603.07079. Token-level switch between reverse-KL (low-entropy teacher tokens) and forward-KL (high-entropy ones); raises high-entropy token retention from 6.8% to 18.5%.
Epi-Verb — Kim, Luo, Kim et al. (2026). Epistemic Verbalization in LLM Reasoning: An Information-Theoretic Framework. https://arxiv.org/abs/2603.15500. Theory companion to Degrade-SD. Frames LLM reasoning as strategic allocation of procedural information (the how-to) and epistemic verbalization (explicit externalization of uncertainty); hindsight-distillation ablation shows removing epistemic tokens (“Wait”, “Let me re-check”) degrades reasoning; distributional-alignment account of “Less Is More” distillation failures.
ERL — Shi, Chen, Jiang, Song, Yang, Zhao (2026). Experiential Reinforcement Learning. https://arxiv.org/abs/2602.13949. Embeds an experience-reflection-consolidation loop into RL training; verbal reflection on failure as PI / text-feedback.
essd — Apple ML Research (2026). Empirical Self-Supervised Distillation: Shape Beats Quality. https://arxiv.org/abs/2604.01193. Self-distilling on a single unfiltered (even high-temperature) model-generated completion improves coding performance — striking case of distributional shaping mattering more than data quality.
ExOPD — Yang, W., Liu, W., Xie, R., K. Yang, S. Yang, Lin (2026). Generalized On-Policy Distillation with Reward Extrapolation. https://arxiv.org/abs/2602.12125. Reformulates OPD as KL-RL with reward scale λ; λ = 1.25 reward extrapolation lets students surpass their teachers, undermining the imitation-ceiling intuition.
Fast-OPD — Yin et al. (2026). Fast On-Policy Distillation via Prefix Truncation. https://arxiv.org/abs/2602.15260. Prefix-truncated student rollouts achieve 2–47× FLOP reduction while matching full-trajectory OPD accuracy.
Forget-SFTRL — Yuan, X., Chen, X., Yu, T., Shi, Jin, Lee, Mitra (2025). Mitigating Forgetting Between Supervised and Reinforcement Learning Yields Stronger Reasoners. https://arxiv.org/abs/2510.04454. Under parameter-update pruning, RL degrades sharply while SFT is robust — RL updates are concentrated on task-critical weights, SFT updates diffuse and largely redundant; proposes a combined SFT+RL recipe (challenging-example selection for SFT, high-entropy-token SFT loss, parameter-freezing of RL-critical weights) that mitigates SFT-RL forgetting using ~1.5% of the SFT data and ~20% of the RL data.
GAD — Ye et al. (2025). Generative Adversarial Distillation for Black-Box Teachers. https://arxiv.org/abs/2511.10643. GAN-discriminator OPD variant for settings where teacher logits are inaccessible; discriminator score replaces the per-token divergence.
GATES — Stein, Huang, Goldstein (2026). GATES: Self-Distillation under Privileged Context with Consensus Gating. https://arxiv.org/abs/2602.20574. PI-OPD with a relevant document as the privileged context plus consensus gating over teacher heads.
GKD — Agarwal, Vieillard, Stanczyk, Ramos, Geist, Bachem (2024). On-Policy Distillation of Language Models: Learning from Self-Generated Mistakes. ICLR. https://arxiv.org/abs/2306.13649. Foundational on-policy KD paper; introduces GKD framework and the JSD/forward-KL/reverse-KL divergence menu over student-generated rollouts.
GLM-5 — Zhipu AI Team (2026). GLM-5 Technical Report. https://arxiv.org/abs/2602.15763. Frontier post-training pipeline ending in OPD-merge of per-domain expert teachers; closing stage replaces a final joint RL pass.
HDPO — Wang et al. (2026). Hint-Augmented Direct Preference Optimization. https://arxiv.org/abs/2603.23871. Routes hard prompts through hint-augmented DPO when GRPO stalls on cliff prompts; PI hint injection breaks the all-zero-advantage degeneracy while preserving preference structure.
MiMo-V2 — Xiaomi LLM-Core Team (2026). MiMo-V2: Multi-Teacher On-Policy Distillation for Olympiad Reasoning and Agentic Tasks. https://arxiv.org/abs/2601.02780. 309B-MoE / 15B-active student; Multi-Teacher OPD as final post-training stage.
MiniLLM — Gu, Dong, Wei, Huang (2024). MiniLLM: Knowledge Distillation of Large Language Models. ICLR. https://arxiv.org/abs/2306.08543. Policy-gradient reverse-KL formulation of LLM distillation; the “treat per-token KL as advantage” recipe that later OPD trainers reuse.
Nemotron-Cascade 2 — NVIDIA (2026). Nemotron-Cascade 2. https://arxiv.org/abs/2603.19220. 30B MoE (3B active) hits Olympiad gold (ICPC/IMO/IOI) via Multi-Domain OPSD consolidation of per-domain experts.
NPO — Yang et al. (2026). Near-Future Policy Optimization. https://arxiv.org/abs/2604.20733. Uses near-future-self checkpoints as teacher; addresses early-training reward sparsity and late-training plateaus by mixing the current policy with a slightly more advanced future-self.
NuRL — Pan et al. (2025). NuRL: Nudging LLMs with Self-Generated Hints via Reinforcement Learning. https://arxiv.org/abs/2509.25666. Self-generated natural-language hints as PI for unsolvable-prompt RL; motivated by Vygotsky’s zone-of-proximal-development.
OEL — Ye et al. (2026). Online Experiential Learning for LLMs. https://arxiv.org/abs/2603.16856. Reward-free post-deployment online learning; uses natural-language skill summaries as PI for unstructured real-world feedback.
OPCD — Ye et al. (2026). On-Policy Context Distillation for Language Models. https://arxiv.org/abs/2602.12275. On-policy counterpart to Context Distillation; internalizes documents / tool manuals / solution traces into weights via context-conditioned teacher and student rollouts.
OPSD — Zhao, Xie, Liu, Huang, Pang, Chen, Grover (2026). Self-Distilled Reasoner: On-Policy Self-Distillation for Large Language Models. https://arxiv.org/abs/2601.18734. Canonical mechanic for same-model PI-OPD; formalizes “teacher does not generate” and the frozen-self + GT-as-PI construction.
OPSDC — Sang, Xu, Zhou, He (2026). On-Policy Self-Distillation for Reasoning Compression. https://arxiv.org/abs/2603.05433. Style-asymmetry PI: teacher conditioned on a concise-prompt instruction shapes the student toward shorter reasoning; 57-59% token reduction with +9-16pp accuracy.
OPSDL — Zhang et al. (2026). OPSDL: On-Policy Self-Distillation for Long-Context Language Models. https://arxiv.org/abs/2604.17535. Same-weight teacher on the load-bearing short-context slice teaches the long-context student; closes the “effective context gap”.
OPD Survey — Song, M., & Zheng, M. (2026). A Survey of On-Policy Distillation for Large Language Models. https://arxiv.org/abs/2604.00626. Field’s first survey of the OPD literature; indexes the ~25+ Q1 2026 wave, taxonomizes divergences and PI forms, and consolidates pathology / fix pairs.
OVD — Xiong, J., Shen, H., Gong, Cheng, J. Shen, Tao, Tan, Bai, Shang, Wong (2026). OVD: On-policy Verbal Distillation. https://arxiv.org/abs/2601.21968. Black-box OPD variant using discrete 0–9 verbal teacher ratings as the per-token signal when logits are unavailable.
Pedagogical RL — Chakraborty, Ziems, et al. (2026, preprint / will-be-paper). Pedagogical Reinforcement Learning for Teacher Training. Pre-paper / blog. Flips the teaching problem: teacher takes question + solution and generates explanations; critiques RLT’s additive form and proposes a multiplicative
R · G_spikereward; claims +9pp on MATH over RLT. Explicitly lightly off-policy by design — teacher-generated trajectories become “self-bootstrapped lightly off-policy mid-training trajectories” for the student, arguing that purely-on-policy learning is itself a bottleneck on cliff prompts.pi-Distill — Penaloza, Vattikonda, Gontier, Lacoste, Charlin, Caccia (2026). Privileged Information Distillation for Language Models. https://arxiv.org/abs/2602.04942. Action-trace PI from a frontier teacher; names the “distributional cliff” pathology qualitatively; joint teacher-student optimization variants.
POPE — Qu et al. (2026). Privileged On-Policy Exploration. https://arxiv.org/abs/2601.18779. Oracle-prefix PI: feeds correct trajectory prefixes to seed exploration on hard problems where GRPO stalls; maintains on-policy gradients while breaking the all-zero-advantage degeneracy.
Qwen3 — Yang et al., Qwen Team (2025). Qwen3 Technical Report. https://arxiv.org/abs/2505.09388. Industrial post-training recipe ending in reverse-KL OPD as the closing stage; source of the “10× cheaper than RL on AIME” headline.
RbD — Chen, H., Razin, N., Narasimhan, K., Chen, D. (2025, Princeton). Retaining by Doing: The Role of On-Policy Data in Mitigating Forgetting. https://arxiv.org/abs/2510.18874. On-policy data preserves non-target capabilities; Llama-3.1-8B IF: SFT −27.8 pts vs RL −3.4 pts at matched target gain; ablations isolate on-policy data collection (not KL reg, not advantage estimation) as the operative mechanism.
REOPOLD — Ko et al. (2026). Reformulating On-Policy Distillation as Policy Optimization with Log-Ratio Rewards. https://arxiv.org/abs/2603.11137. Recasts OPD as policy-gradient with clipped log-ratio reward; reports 6.7–12× sample efficiency over ProRL on AIME-25 and MathVista.
RESD — Zhang, Y., Li, S., Yu, C., et al. (2026). Learning with Rare Success but Rich Feedback via Reflection-Enhanced Self-Distillation. arXiv preprint (no ID yet). Student-generated reflection on a failed rollout enriches the SDPO self-teacher’s context as privileged information; reflection tokens themselves are not scored. Closest published instantiation of the “reflection-as-PI” variant of RA-OPD (Appendix D).
Rethinking-OPD — Li, Y., Zuo, Y., He, B., et al. (2026, Tsinghua). Rethinking On-Policy Distillation of LLMs: Phenomenology, Mechanism, and Recipe. https://arxiv.org/abs/2604.13016. Systematic study of when/why OPD succeeds or fails. Two main contributions: (a) predictive framework — three tracking metrics (overlap ratio = top-\(k\) token overlap; overlap-token advantage = alignment on shared tokens; entropy gap), and two necessary conditions for OPD success (thinking-pattern compatibility between student and teacher; teacher offers genuinely new capabilities — same-family larger teachers add nothing, post-trained teachers with new RL skills do); (b) depth-degradation pathology — per-position teacher signal quality degrades with trajectory depth, eroding the per-token learning signal in long CoTs and multi-turn agentic settings. Also reports that optimizing only the overlap tokens matches full top-\(k\) OPD (non-overlap tokens contribute little).
Revisit-OPD — Fu et al. (2026). Revisiting On-Policy Distillation: Local Support and Sampled-Token Bias. https://arxiv.org/abs/2603.25562. Top-\(k\) local-support matching to address long-CoT instability and sampled-token bias in standard OPD estimators.
RFT-Continual — Lai, S., Zhao, H., Feng, R., et al. (2025). Reinforcement Fine-Tuning Naturally Mitigates Forgetting in Continual Post-Training. https://arxiv.org/abs/2507.05386. Group-normalized advantage downweights uncertain rollouts, providing implicit data-dependent regularization at the advantage-estimator level; offered as a continual-learning explanation complementary to (or downstream of) on-policy-data and sparse-subnet accounts.
RL-Subnet — Mukherjee, S., Yuan, L., Hakkani-Tür, D., Peng, H. (UIUC, 2025). Reinforcement Learning Finetunes Small Subnetworks in Large Language Models. https://arxiv.org/abs/2505.11711. RL induces sparse parameter updates intrinsically — only 5–30% of weights are modified across 7 RL algorithms (PPO, GRPO, DPO, ORPO, KTO, SimPO, PRIME) × 10 LLMs from different families, without any explicit sparsity regularization. Finetuning the subnetwork alone recovers full-finetune accuracy. Attributes the sparsity to on-policy data, not KL or advantage estimation — a finding that complicates any framing of “sparse updates” as an orthogonal alternative to “on-policy data” for explaining RL’s capability-preservation behaviour.
ROPD — Fang, J., Hong, Z., Zheng, M., Song, M., G. Li, Jiang, D. Zhang, Guo, X. Wang, Chua (2026). Rubric-based On-Policy Distillation: Black-Box Distillation via Teacher-Induced Criteria. https://arxiv.org/abs/2605.07396. Black-box OPD variant for proprietary teachers: teacher acts as Rubricator (generating prompt-specific textual criteria with importance weights) and Verifier (binary-grading student rollouts against each criterion); the weighted pass rate becomes the GRPO reward. Trades surface-form mimicry of logit-based OPD for semantic-principle supervision; trajectory-level signal vs OVD’s per-token scalar.
RL²F — Klissarov, Cook, Antognini, Sun, Li, Jaques, Musat, Grefenstette (2026). Improving Interactive In-Context Learning from Natural Language Feedback. https://arxiv.org/abs/2602.16066. Meta-learning from language feedback; trains a teacher to convert NL critique into student-usable signal. Companion paper: SML.
RL’s Razor — Shenfeld, I., Pari, J., Agrawal, P. (2025). RL’s Razor: Why Online Reinforcement Learning Forgets Less. https://arxiv.org/abs/2509.04259. On-policy RL implicitly biased toward KL-minimal solutions among those that solve the new task; forgetting determined by KL between fine-tuned and base policy on the new task.
RLAD — Zhang, Jiang, Shen, Zhang, Ram, Yang, Tu, Xia, Soatto (2026). RLAD: Reinforcement-aware Knowledge Distillation for LLM Reasoning. https://arxiv.org/abs/2602.22495. Action-trace distillation combined with RL; routes between OPD and RL update modes per sample.
RLSD — Li et al. (2026). Reinforcement Learning with Self-Distillation: PI-Leakage Analysis. https://arxiv.org/abs/2604.03128. PI-leakage analysis showing how the conditioning signal contaminates downstream rollouts under standard reverse-KL OPSD; complements CaOPD’s calibration argument.
RLT — Cetin, E., Zhao, T., Tang, Y. (Sakana AI, 2025). Reinforcement Learning Teachers of Test Time Scaling. https://arxiv.org/abs/2506.08388. Trains an RL teacher that takes question + solution and generates explanations; additive reward
r = r_SS − λ · r_KLcouples student log-prob of the solution with think-token interpretability; a 7B RLT beats much larger off-the-shelf teachers as a distillation source.RLTF — Song, Chen, Tajwar, Munos, Pathak, Bagnell, Singh, Zanette (2026). RLTF: Expanding the Capabilities of Reinforcement Learning via Text Feedback. https://arxiv.org/abs/2602.02482. Text-feedback PI: turns environment responses (runtime errors, judge evaluations) into dense per-token supervision for RL on reasoning and coding.
SAGE — Liao, B., Dong, H., Xu, X., Monz, Bian (2026). Self-Hint Aligned GRPO with Privileged Supervision. https://arxiv.org/abs/2602.03143. Diagnoses GRPO stall under sparse rewards; injects PI hints (online self-hint generator conditioned on the compressed reference solution) to reshape the rollout distribution without modifying the reward function, restoring on-policy gradients on cliff prompts.
SD-Zero — Princeton / UToronto / CMU (2026). Self-Distillation Zero: Dense Self-Supervision from Binary Rewards. https://arxiv.org/abs/2604.12002. Turns sparse binary correctness into dense token-level signal by having the model rewrite its own failed attempt and distilling the revision back; reflection-as-PI in the binary-reward regime.
SCOPE — Zheng, Ma, Liang, Ruan, Fu (2026). SCOPE: Signal-Calibrated On-Policy Distillation Enhancement with Dual-Path Adaptive Weighting. https://arxiv.org/abs/2604.10688. Diagnoses the “Flawed Prefix Trap” — teacher guidance becomes unreliable on unusual student prefixes (recovery rate drops with teacher perplexity on the student’s input) — and proposes outcome-driven branching plus dual-perspective adaptive weighting.
SDFT — Shenfeld, I., Damani, M., Hübotter, J., Agrawal, P. (2026, MIT Improbable AI + ETH Zürich). Self-Distillation Enables Continual Learning. https://arxiv.org/abs/2601.19897. EMA-OPSD prevents catastrophic forgetting on a 3-task sequential suite (Tool-Use → Science Q&A → Medical); same-model teacher conditioned on demonstrations via ICL; mathematically equivalent to on-policy RL with an implicit reward.
SDPO — Hübotter et al. (2026). Self-Distillation Policy Optimization. https://arxiv.org/abs/2601.20802. Peer-rollout PI: leverages successful student rollouts and rich textual feedback (runtime errors, judge evaluations) for credit assignment in RLVR.
Skill-SD — Wang et al. (2026). Skill-Conditioned Self-Distillation for LLM Agents. https://arxiv.org/abs/2604.10674. Skill-summary PI: compact natural-language summaries of prior attempts as privileged context for the teacher in multi-turn agentic settings; student internalizes skill logic without seeing skills at inference.
SML — Klissarov et al. (2026). Self-Meta-Learning from Language Feedback. https://arxiv.org/abs/2602.16488. Companion to RL²F; trains the teacher as a separable skill of converting natural-language feedback into student-usable per-token signal.
SRPO — Li, Yang, Fang, Song, Zheng (2026). Sample-Routed Policy Optimization: Unifying Group-Relative and Self-Distillation Policy Optimization via Sample Routing. https://arxiv.org/abs/2604.02288. Sample-level routing between GRPO (correct rollouts) and SDPO (incorrect rollouts where a successful sibling exists); diagnoses correct-sample ambiguity and signal-reliability degradation as the failure modes that motivate routing.
Stable-OPD — Jang et al. (2026). Stable On-Policy Distillation via P_T · P_S^β Reformulation. https://arxiv.org/abs/2601.07155. Variance-reducing gradient reformulation that interpolates teacher and student distributions before log; numerics-only fix orthogonal to mode-seeking/covering choice.
TAMTRL — Wang, L., Wang, Y., Yu, X., Zhang, K., Peng, T., Wu, W. (2026, Beihang). Teacher-Aligned Reward Reshaping for Multi-Turn Reinforcement Learning in Long-Context Compression. https://arxiv.org/abs/2603.21663. Turn-level credit assignment for multi-turn RL on long documents; teacher with full-document context produces normalized per-turn probabilistic rewards used as dense supervision under Centralized Training with Decentralized Execution.
Tinker — Lu, K. (2025). On-Policy Distillation (Thinking Machines blog). https://thinkingmachines.ai/blog/on-policy-distillation/. Canonical practitioner statement of OPD’s 50–100× compute claim and the O(N) vs O(1) information-rate framing; reverse-KL recipe on Qwen3 via the Tinker cookbook.
VarReason — Zhou, X., Z. Liu, Wang, Du, Lin, C. Li, L. Wang, Pang (2025). Variational Reasoning for Language Models. https://arxiv.org/abs/2509.22637. Variational inference over latent reasoning traces; derives an ELBO over reasoning + answer that exposes the implicit difficulty bias of GRPO as a term in the gradient. Frames OPD/RL as point estimates of a broader variational objective.
VLA-OPD — Zhong, Yan, Li, He, Zhang (2026). VLA-OPD: Bridging Offline SFT and Online RL for Vision-Language-Action Models via On-Policy Distillation. https://arxiv.org/abs/2603.26666. Three-phase loop (on-policy sampling → dense teacher labeling → mode-seeking reverse-KL update) that ports the OPD recipe to robotic Vision-Language-Action models, replacing sparse-reward RL with token-level supervision.
VOLD — Chen et al. (2025). Visual On-Policy Language Distillation. https://arxiv.org/abs/2510.23497. Transfers text-LLM reasoning into VLMs via on-policy KL + GRPO without visual reasoning data; demonstrates modality-agnostic transfer of next-token-distribution shape.
X-KD — Cai, Y., & Yuan, Y. (2026). X-KD: Inverse-RL On-Policy Knowledge Distillation. https://arxiv.org/abs/2602.12674. Uses Bayesian IRL (AVRIL) to recover an implicit reward from teacher behavior, then wraps OPD with an experiential regularizer derived from that reward. Argues OPD is best understood as IRL, not divergence-matching.
X-OPD — Lin et al. (2026). Cross-Modal On-Policy Distillation for Speech-Text Reasoning. https://arxiv.org/abs/2603.24596. Closes speech-text reasoning gap with per-token KL recipe; symmetric counterpart to CORD in the speech-language direction.
zhuokaiz post — Zhao, Zhuokai (Senior Research Scientist, Meta AI Research; PhD UChicago) (2026). Four Failure Modes of On-Policy Distillation. X thread. https://x.com/zhuokaiz/status/2055042099674796118. Synthesizes Rethinking-OPD, DemysOPD, Revisit-OPD into the “local-menu communication protocol” mechanism for OPD; four failure modes (different-language menus, locally-rewarded repetition, one-token-as-menu-proxy, per-position gradient cancellation) are facets of one fragile teacher-student protocol over a small local vocabulary.